Внедрение систем искусственного интеллекта (ИИ) на базе нейронных сетей архитектуры трансформер и генеративных больших языковых моделей (LLM) в клиническую практику представляет собой один из наиболее значимых и противоречивых сдвигов в истории развития медицинских технологий.
В отличие от традиционных систем машинного обучения (ML), которые функционировали на основе зафиксированных, так называемых «закрытых» (locked) алгоритмов и детерминированных правил классификации, современные LLM обладают вероятностной природой.
Эта архитектурная особенность порождает критическое противоречие: медицинская диагностика, назначение терапии и ведение электронной медицинской документации требуют детерминированного, юридически значимого и математически доказуемого подхода, в то время как LLM по своей фундаментальной сути являются стохастическими системами предсказания следующего токена.
Данное базовое несоответствие между вероятностным механизмом генерации и строгими требованиями доказательной медицины приводит к появлению уникальных векторов риска. К ним относятся феномены «тихих отказов» (silent failures), эмерджентное рассогласование при обработке сверхдлинных контекстов электронных медицинских карт (EHR) и системная деградация клинических алгоритмов в реальном времени, усугубляемая систематической «ошибкой выжившего» (survivorship bias) в ретроспективных исследованиях.
В условиях, когда, по данным исследований 2024-2025 годов, около 31% взрослых пациентов в развитых странах уже используют LLM для получения предварительных объяснений своих симптомов до консультации с врачом, проблема безопасности этих систем выходит за рамки сугубо академического дискурса и становится вопросом национальной инфраструктурной безопасности.
Настоящий аналитический отчет представляет собой исчерпывающее исследование проблем интеграции автономных ИИ-агентов в строго регулируемые контуры здравоохранения. В документе детально рассматриваются эволюция мировых и российских нормативно-правовых баз (включая стандарты FDA, EU AI Act и новейшие ГОСТ Р), природа системных ошибок нейронных сетей, методы количественной оценки неопределенности (Uncertainty Quantification, UQ) и передовые методологии формальной верификации (с использованием конечных автоматов и линейной темпоральной логики) для создания доказуемо безопасных программных медицинских изделий, классифицируемых как Software as a Medical Device (SaMD).
Эволюция глобальных и национальных нормативно-правовых парадигм (2010–2026 гг.)
Исторически регулирование медицинского программного обеспечения, классифицируемого Международным форумом регуляторов медицинских изделий (IMDRF) как SaMD, выстраивалось вокруг концепции статических, неизменяемых моделей.1 В период активного внедрения раннего медицинского ИИ (2010–2015 годы) золотым стандартом считалась сертификация «закрытых алгоритмов», весовые коэффициенты и логика которых замораживались перед выходом на коммерческий рынок.1 Однако адаптивная природа современных LLM и систем непрерывного обучения потребовала радикального пересмотра регуляторных парадигм на глобальном уровне, так как старые методы не способны оценивать системы, которые эволюционируют с каждой новой итерацией данных.
Концептуальный сдвиг FDA: TPLC, PCCP и проблемы генеративных моделей
Агентство Министерства здравоохранения и социальных служб США (FDA) официально признало, что традиционная парадигма регулирования медицинских устройств неприменима к адаптивному искусственному интеллекту и технологиям машинного обучения.6 В ответ на этот вызов был разработан и внедрен подход, основанный на непрерывном мониторинге на протяжении всего жизненного цикла продукта (Total Product Life Cycle — TPLC).
Ключевым этапом этой эволюции стал выпуск в конце 2024 — начале 2025 года пакета руководящих документов, включая проект руководства по управлению жизненным циклом (Docket FDA-2024-D-4488) и окончательное руководство по «Заранее определенному плану контроля изменений» (Predetermined Change Control Plan — PCCP) для функций программного обеспечения устройств на базе ИИ (AI-DSF).
Концепция PCCP революционизирует процесс обновления: она позволяет производителям легально вносить заранее оговоренные и научно обоснованные итеративные изменения в алгоритмы (например, дообучение на новых когортах пациентов для снижения демографической предвзятости) без необходимости прохождения повторной длительной процедуры маркетингового одобрения (PMA) или получения нового разрешения 510(k) при каждом обновлении.
Структура юридически одобренного PCCP строго регламентирована и включает три обязательных компонента, которые оцениваются FDA:
- Описание модификаций (Description of Modifications): Точная, исчерпывающая спецификация того, какие параметры модели будут изменяться (например, адаптация под новые протоколы визуализации или изменение целевой популяции).
- Протокол модификаций (Modification Protocol): Детальная методология того, как компания будет разрабатывать, валидировать (с предоставлением объективных доказательств согласно 21 CFR 820.3(z)) и внедрять каждое изменение. Протокол должен включать метрики, пропорциональные клиническому риску.
- Оценка воздействия (Impact Assessment): Совокупный анализ потенциальных рисков и выгод от планируемых изменений, включая детальную оценку алгоритмической предвзятости (bias) и методы ее смягчения на индивидуальном и кумулятивном уровнях.12
Несмотря на эти инновации, по состоянию на конец 2024 года, хотя FDA одобрило в общей сложности 1016 медицинских устройств с использованием ИИ/ML, лишь 53 из них функционировали на базе утвержденных планов PCCP.10 Более того, только 15 из них были отнесены к категории генеративных ИИ.10 Подавляющее большинство одобренных систем остаются узкоспециализированными ML-инструментами (например, для сегментации КТ-снимков), а не автономными агентами.
Осознавая этот разрыв, 20 ноября 2024 года FDA провело первое заседание Консультативного комитета по цифровому здравоохранению (DHAC), полностью посвященное влиянию генеративного ИИ на безопасность медицинских устройств. В фокусе внимания оказались не столько инструменты радиологии, сколько новые классы продуктов: «цифровые ИИ-терапевты» и чат-боты для поддержки ментального здоровья, которые генерируют неограниченные варианты ответов (unbounded outputs) на нестандартизированные входные данные пользователя, часто без какого-либо надзора со стороны врача (HCP).
Комитет констатировал, что подобные системы создают новые векторы риска, включая киберугрозы, когда злоумышленники могут использовать состязательные примеры (adversarial examples) или внедрять бэкдоры на этапе обучения для провоцирования смещения производительности (performance drift). Для стандартизации оценки таких уязвимостей FDA даже разработало специализированный каталог инструментов регуляторной науки, включающий программное обеспечение bias.myti.report. Данный Python-инструмент позволяет разработчикам искусственно усиливать предвзятость ИИ-моделей (через количественное искажение или индуктивное трансферное обучение), чтобы проверить устойчивость их внутренних алгоритмов смягчения рисков.
Требования Европейского Союза: Синтез MDR и AI Act
В Европейском Союзе регулирование медицинского программного обеспечения на базе генеративного ИИ формируется на комплексном пересечении исторического Регламента о медицинских изделиях (EU MDR или IVDR для диагностики in vitro) и нового беспрецедентного Закона об искусственном интеллекте (EU AI Act). Важно подчеркнуть, что AI Act не заменяет MDR, а создает дополнительный, наслаивающийся контур обязательств.
Программное обеспечение, которое квалифицируется как ИИ-система и одновременно является частью медицинского устройства, подлежащего оценке соответствия с привлечением нотифицированного органа (Notified Body) по правилам MDR, автоматически классифицируется как ИИ-система «высокого риска» (High-Risk AI system) в терминологии AI Act или Medical Device Artificial Intelligence (MDAI) согласно руководствам MDCG.
Хотя базовые генеративные модели общего назначения (GPAIM), такие как ChatGPT, сами по себе не относятся к высокорисковым и подлежат лишь требованиям прозрачности, их интеграция в специализированное SaMD кардинально меняет их статус. Переходный период строго регламентирован:
- Для ИИ-систем высокого риска, выпущенных на рынок до 2 августа 2026 года, требования AI Act применяются только в случае внесения «существенных изменений в конструкцию» после этой даты.
- Для провайдеров GPAIM, выпущенных до 2 августа 2025 года, крайний срок соответствия обязательствам AI Act установлен на 2 августа 2027 года.
- Если высокорисковая система предназначена для использования государственными органами здравоохранения, дедлайн смещается на 2 августа 2030 года.
Требования AI Act глубоко интегрируются с действующими стандартами системы менеджмента качества (QMS), такими как ISO 13485, и стандартами жизненного цикла медицинского ПО (IEC 62304).17 В частности, AI Act устанавливает жесткие продуктовые требования к архитектуре медицинских LLM:
- Обеспечение объяснимости (Explainability): Система обязана генерировать не только финальный ответ, но и «выходные данные объяснимости», такие как трассировка логических рассуждений (reasoning traces) на естественном языке для систем NLP или тепловые карты для радиологии.
- Управление данными и предвзятостью: Производители обязаны документировать все обучающие, валидационные и тестовые наборы данных в специализированном Файле управления данными (Data Governance File), включая подтверждение происхождения данных (provenance), очистку и проверку качества. Валидационные исследования должны охватывать разнообразные популяции для минимизации систематической предвзятости по гендерным, возрастным и этническим признакам.
- Архивирование и пострыночный надзор (PMS): AI Act требует непрерывной оценки соответствия продукта на этапе пострыночного надзора. Документация (технические файлы, записи об изменениях, декларации соответствия) должна храниться в течение 10 лет после вывода системы на рынок, а автоматически сгенерированные рабочие логи (протоколы) системы — не менее 6 месяцев.
| Регуляторный орган / Акт | Ключевые инициативы 2024–2026 гг. | Специфические требования к медицинским ИИ-системам | Даты вступления в силу / Статус |
| США (FDA) | Внедрение TPLC и PCCP; фокус на генеративные чат-боты (заседание DHAC). | Предварительно утвержденный план контроля изменений (PCCP), включающий протокол модификаций и оценку кумулятивного воздействия дрейфа данных. | Окончательные руководства опубликованы в конце 2024 — начале 2025 гг.. |
| Евросоюз (AI Act + MDR) | Классификация SaMD с участием нотифицированных органов как систем «высокого риска» (MDAI). | Обязательная генерация трассировок объяснимости, уведомление пользователей о взаимодействии с ИИ, хранение логов в течение 6 месяцев. | Полное применение для систем высокого риска с 2 августа 2027 г. (для гос. органов с 2030 г.). |
| Россия (Росстандарт, Росздравнадзор) | Введение серии национальных стандартов (ГОСТ Р) и создание АИС для мониторинга. | Обязательная автоматическая передача данных о работе ИИ в АИС Росздравнадзора; поддержка обмена данными в формате СЭМД в 2025 г.. | ГОСТ Р 72484-2025 (с 1 фев 2026); ГОСТ Р 71671-2024 (с 1 янв 2025); Приказ Росздравнадзора до конца 2025 г.. |
Национальная стандартизация и институциональный надзор в Российской Федерации
В Российской Федерации регулирование применения ИИ в здравоохранении перешло от общих рекомендаций к фазе активной технической стандартизации и внедрения систем объективного государственного контроля в реальном времени. Вектор развития направлен на создание надежной инфраструктуры, способной интегрировать автономные системы в сложный контур государственной и частной медицины.
Ключевым событием стало вступление в силу с 1 февраля 2026 года национального стандарта ГОСТ Р 72484-2025 «Системы искусственного интеллекта в клинической медицине. Термины, определения и классификация». Хотя в российской правовой системе стандарты ГОСТ по общему правилу являются добровольными (если иное не предусмотрено специальными нормативными актами), практическое значение этого документа колоссально. Он унифицирует лексикон для иностранных производителей, разработчиков программного обеспечения, отделов закупок больниц и регуляторов, снижая уровень критической путаницы в технических файлах, инструкциях и государственных контрактах.
Этот базовый стандарт органично дополняет ранее принятые профильные документы, формирующие комплексный инженерный каркас:
- ГОСТ Р 71671-2024 «Системы для поддержки принятия врачебных решений (СППВР) с использованием искусственного интеллекта» (вступил в силу 1 января 2025 года).
- ГОСТ Р 71672-2024 «Системы предиктивной аналитики на базе искусственного интеллекта в клинической медицине» (утвержден в конце октября 2024 года).24
- ГОСТ Р 59921.11-2025, регламентирующий требования к наборам данных для тестирования и контроля универсальности алгоритмов.
Помимо стандартизации терминологии и процессов, российские регуляторы ужесточают требования к прямому надзору за функционирующими моделями. Росздравнадзор утвердил беспрецедентный порядок, обязывающий производителей медицинских изделий с ИИ в автоматическом режиме передавать телеметрические данные об их работе в специализированную автоматизированную информационную систему (АИС) ведомства. Этот механизм, действующий согласно приказу до конца 2025 года, задуман как аналог системы фармаконадзора: в систему через электронный кабинет заявителя непрерывно поступают сведения о количестве проведенных исследований и результатах работы алгоритмов без участия конечного пользователя-врача. На момент введения этой нормы в России легально обращалось 48 зарегистрированных ИИ-медизделий, 43 из которых были разработаны отечественными вендорами. Эксперты отмечают, что данный подход позволит регулятору в реальном времени отслеживать деградацию качества моделей и выявлять инциденты, хотя он и вызывает дискуссии в профессиональной среде относительно конфиденциальности агрегируемых клинических данных.
Дополнительным административным драйвером, обеспечивающим прозрачность клинических ИИ-агентов, является категорическое требование интеграции с сервисами структурированных электронных медицинских документов (СЭМД), вступающее в полную силу в 2025 году. Без гарантированного, стандартизированного обмена данными в формате СЭМД частные и государственные клиники лишаются возможности легально функционировать, участвовать в национальных проектах и проходить лицензионные проверки Минздрава. Это требование охватывает широкий спектр амбулаторных и диагностических специальностей (терапевтов, неврологов, врачей УЗД, рентгенологов) и диктует жесткие архитектурные ограничения для разработчиков LLM-агентов: система, формирующая выписку или протокол исследования, должна быть абсолютно детерминированной в формировании выходных XML/JSON структур, не допуская галлюцинаций в кодировке диагнозов или полях метаданных.
Анатомия ошибок ИИ в клинических условиях: от ограничений архитектуры к эпистемологическим сбоям
Для того чтобы выстроить адекватную систему защиты, необходимо глубоко понимать природу сбоев, генерируемых моделями машинного обучения. Классические программные ошибки в традиционных медицинских устройствах детерминированы: они возникают из-за логических недочетов в коде и могут быть воспроизведены путем репликации условий. Ошибки человека-врача статистически распределены, подвержены известным когнитивным искажениям (например, усталости в конце смены) и часто перехватываются на этапах коллегиальной или сестринской проверки.1 Ошибки же генеративного искусственного интеллекта носят принципиально иной, часто контринтуитивный характер. Они могут быть сконцентрированы в специфических демографических кластерах из-за предвзятости данных или оставаться абсолютно невидимыми в рутинном рабочем процессе.
Проблема сверхдлинных контекстов: Эмерджентное рассогласование и феномен «Lost in the Middle»
Стремительное развитие функционала больших языковых моделей породило амбициозную цель: использование автономных агентов для целостного анализа обширных электронных медицинских карт (EHR). Сложная история болезни пациента с хроническими заболеваниями, включающая многолетние выписки, результаты тысяч лабораторных тестов, протоколы операций и неструктурированные заметки врачей, может легко достигать объема в 300 000 – 500 000 токенов. При обработке таких массивов данных проявляется опасный феномен эмерджентного рассогласования (emergent misalignment) — непредсказуемое, системное отклонение ИИ-агента от заложенных на этапе тонкой настройки (fine-tuning) паттернов безопасного поведения. Под когнитивным давлением огромного объема часто противоречивого клинического текста агент начинает «забывать» первоначальные инструкции по безопасности.
Фундаментальный аппаратный и алгоритмический недостаток архитектуры трансформеров, препятствующий надежному анализу EHR, был выявлен в знаковых исследованиях 2024–2025 годов и получил название проблема «Потерянного в середине» (Lost in the Middle).4 Несмотря на то, что производители ведущих коммерческих моделей (таких как GPT-4 или Claude 3) маркетингово заявляют о поддержке колоссального контекстного окна в 1 миллион токенов и почти стопроцентном поиске «иглы в стоге сена», в реальных сложных задачах, требующих клинической интеграции фактов, способность моделей извлекать и применять критически важную информацию, скрытую в середине документа, резко деградирует.4
Испытания показали тревожную динамику: точность точного совпадения (exact match) при извлечении фактов постепенно снижается и составляет 87% при объеме входных данных в 500 000 токенов, падая до 84% на отметке 900 000 токенов. Еще более критично поведение при нечетком поиске (fuzzy match), который имитирует реальный клинический анализ семантически связанных фактов: после преодоления порога в 500 000 токенов производительность рушится, достигая неприемлемых 69% точности при 900 000 токенах.
В условиях клинической практики это означает, что ИИ-агент, анализирующий историю болезни, может успешно прочитать жалобы при поступлении (начало промпта) и текущие анализы (конец промпта), но полностью проигнорировать жизненно важное упоминание о тяжелой аллергической реакции на антибиотик или имплантированном кардиостимуляторе, задокументированном в середине досье несколько лет назад. Наличие контекстного окна в 1 миллион токенов не гарантирует, что модель эффективно распорядится всем этим объемом рабочей памяти при принятии решений, что делает бесконтрольное скармливание EHR агентам крайне опасной практикой.
Инфраструктура «Тихих отказов» (Silent Failures) и гиперуверенность LLM
Самым коварным и опасным классом сбоев в медицинских системах на базе LLM признаны «тихие отказы» (silent failures). Тихий отказ определяется как критический системный сбой, при котором генеративная модель выдает абсолютно неверный с клинической точки зрения результат (диагноз, дозировку, интерпретацию), не демонстрируя никаких внешних признаков системной ошибки, программного сбоя, отказа от ответа или хотя бы снижения уровня текстовой уверенности.
В отличие от классического ПО, которое выдаст код ошибки при невозможности обработать данные, LLM генерирует текст с присущим ей синтаксическим апломбом, скрывая фундаментальный диагностический провал за грамматически безупречным фасадом.1 Эксперты Всемирного экономического форума (WEF) и аналитики здравоохранения отмечают, что подобная непрозрачность и ложная уверенность могут легко спровоцировать каскад катастрофических медицинских потерь, если такие системы интегрированы в процессы принятия решений без предохранительных контуров.
Масштабы диагностической некомпетентности LLM в ситуациях клинической неопределенности были наглядно продемонстрированы в масштабном исследовании PrIME-LLM.36 В ходе исследования проверялась клиническая аргументация 21 ведущей коммерческой языковой модели на базе 29 стандартизированных клинических сценариев (vignettes), включавших историю настоящего заболевания, физикальные осмотры и результаты лабораторных тестов. Оценка проводилась в формате вопросов «выбрать все подходящие варианты» (select-all-that-apply), имитируя реальный диагностический процесс.
Результаты оказались обескураживающими: уровень отказов (failure rate) при формулировании дифференциального диагноза превысил 0.80 (80%) абсолютно у всех исследованных моделей без исключения.36 В то время как модели неплохо справлялись с угадыванием «окончательного диагноза» на поздних этапах (где данные очевидны), их способность к самостоятельному клиническому мышлению на ранних этапах оказалась ничтожной. Топовые модели, такие как Grok (0.78 балла), GPT-4.5, Claude 4.5 Opus и Gemini 3.0 Flash, показали лишь относительное превосходство над более слабыми версиями, такими как Gemini 1.5 Flash (0.64 балла).36
| Категория моделей в исследовании PrIME-LLM | Примеры протестированных систем | Средний балл PrIME-LLM | Уровень отказов в дифференциальной диагностике |
| Высшая квартиль производительности | Grok 4, GPT-4.5, Claude 4.5 Opus, Gemini 3.0 Flash | 0.77 – 0.79 | > 80% |
| Низшая квартиль производительности | Gemini 1.5 Flash | 0.63 – 0.65 | > 80% |
| Примечание: Разница между определением окончательного диагноза и назначением диагностического тестирования для передовых моделей (напр. GPT-4o) составляла в среднем 0.12 пункта, подчеркивая слабость в процедурном планировании.36 |
Ключевым паттерном, выявленным в исследовании PrIME-LLM, стал феномен «преждевременного коллапса» (premature collapse). Сталкиваясь со сложным набором симптомов, LLM не выстраивали широкое дерево дифференциальных диагнозов, как это делает живой врач, а чрезмерно быстро и гиперуверенно фиксировались на одной единственной диагностической гипотезе, игнорируя альтернативы.36 Примечательно, что этот эффект ложной уверенности и высокого процента ошибок особенно остро проявлялся на клинических кейсах молодых пациентов и людей среднего возраста, в то время как в педиатрических случаях (за исключением дифференциальной диагностики) модели вели себя стабильнее.36 Аналогичные выводы получены на бенчмарках mARC-QA и M-ARC, где современные state-of-the-art модели (o1, Gemini, Claude, DeepSeek) демонстрировали острый недостаток базового медицинского здравого смысла, склонность к галлюцинациям и завышенную самоуверенность (overconfidence), значительно уступая реальным врачам.37 Оборотной стороной медали является исследование Гарвардского университета, где в узкоспециализированной задаче по триажу в отделении неотложной помощи модель OpenAI «o1 preview» (первая модель с цепочкой рассуждений) превзошла врачей, особенно на этапе первичного поступления пациента, когда информации минимум.39 Однако, как показывают бенчмарки реальных электронных систем (MedAgentBench от Стэнфорда), изолированный успех в ответах на вопросы USMLE не гарантирует способности агента выполнять многошаговые задачи автономно внутри зашумленной среды реальной больницы.40
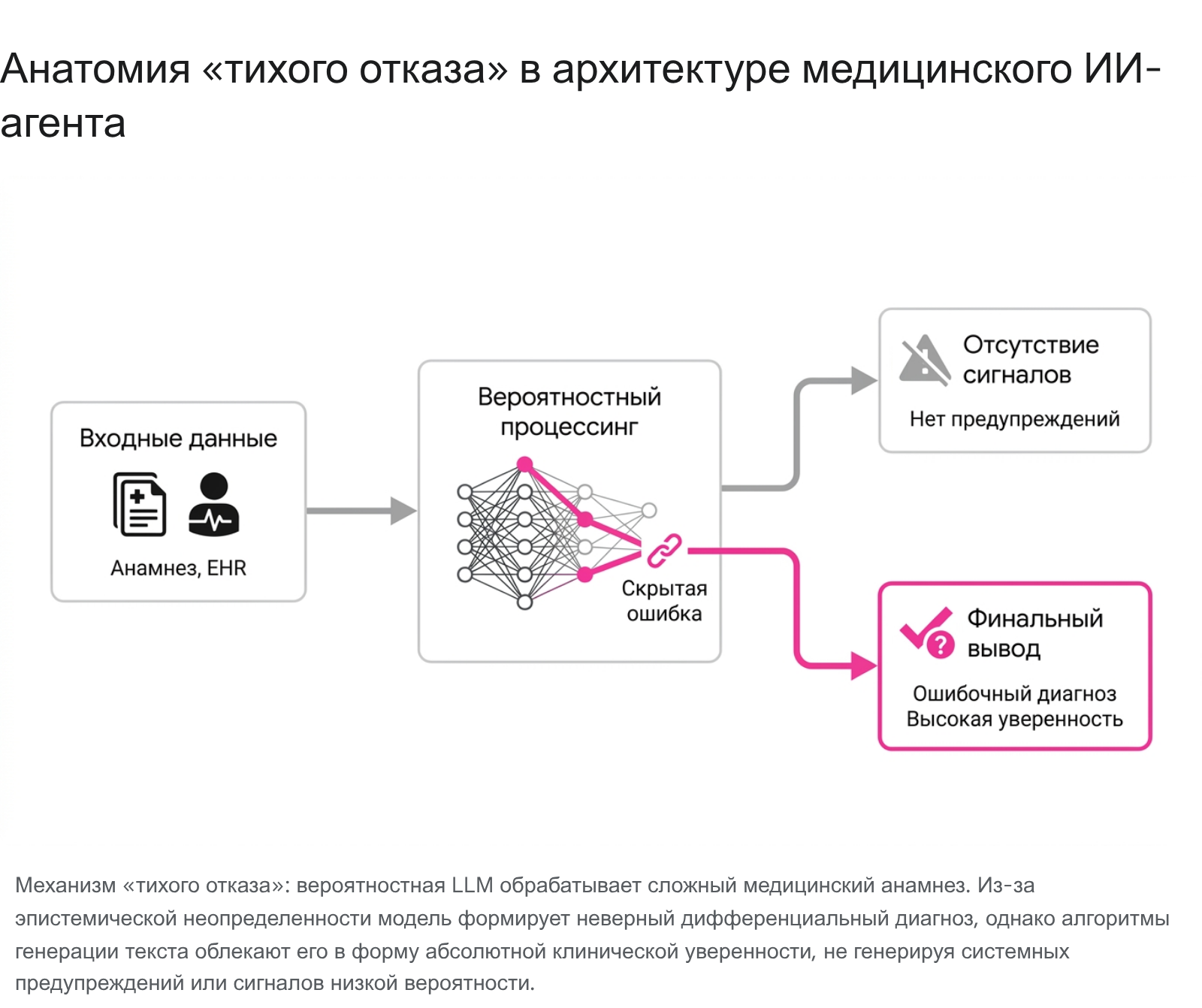
Детальный разбор природы «тихого отказа» был проведен в рамках исследования системы мета-верификации SCOUT (Scalable Clinical Oversight via Uncertainty Triangulation) в 2024–2025 годах.41 SCOUT был разработан как агностический фреймворк для перехвата галлюцинаций LLM и маршрутизации неуверенных ответов к врачу-человеку. Система использует три ортогональных метода проверки: гетерогенность моделей (сверка результатов архитектурно разных LLM), стохастическую непоследовательность (проверка стабильности ответов одной модели при многократном запросе) и критику логики (аудит цепочки рассуждений дополнительной моделью-чекером).41
Несмотря на высокую общую эффективность системы (снижение нагрузки на врачей от 45% до 83%), исследователи задокументировали случай абсолютного, сквозного «тихого отказа».41 Нейросеть анализировала текст отчета компьютерной томографии (КТ), в котором описывались «диффузные очаги низкой плотности».41 Ни одна из трех стратегий верификации не подняла тревогу, и ИИ выдал уверенный, но в корне неверный диагноз. Последующий клинический разбор показал, что ошибка коренилась не в логическом сбое трансформера, а в глубокой внутренней двусмысленности самого исходного текста. Текст отчета КТ просто не содержал необходимой морфологической детализации, чтобы любой субъект (человек или алгоритм) мог достоверно отличить доброкачественные регенеративные узлы от злокачественной формы рака печени. Чтобы провести это различие, требовался оригинальный визуальный пересмотр самих DICOM-снимков, а не анализ текста.41 Этот критический кейс очерчивает предельные границы возможностей NLP в медицине: алгоритмы мета-верификации текстового вывода разделяют тот же самый «информационный потолок», что и анализируемый текст. Если исходные данные неполноценны, принуждение модели к выдаче единственного ответа неизбежно порождает тихий отказ, маскирующий дефицит данных под ложную экспертность.41
Эпидемиология алгоритмического смещения и «Ошибка выжившего»
В контексте внедрения ИИ в клиническую рутину, термины алгоритмическое смещение (algorithmic bias) и «ошибка выжившего» (survivorship bias) приобретают фатальное значение. Ошибка выжившего в клиническом ML возникает как систематическое когнитивное и статистическое искажение: научное сообщество, разработчики и администраторы клиник фокусируются исключительно на пациентах, лечение которых прошло успешно благодаря ИИ, или на моделях, показавших блестящие результаты на тепличных датасетах.1 При этом уверенные, но ошибочные машинные диагнозы, которые врачи приняли без критической верификации (и которые привели к ухудшению состояния пациентов или неоптимальным маршрутам маршрутизации), остаются незамеченными и не документируются в обучающих петлях обратной связи.1 Как и в знаменитом историческом примере Абрахама Вальда с бронированием бомбардировщиков во время Второй мировой войны, инженеры пытаются «укреплять» алгоритмы там, где они и так работают, игнорируя области невидимых, «смертельных» промахов.2
Корни этой проблемы лежат на самых ранних этапах жизненного цикла ИИ 29:
- Неотъемлемая предвзятость данных (Inherent Bias): Обучающие датасеты (EHR) отражают историческое социальное неравенство. Например, женщины и этнические меньшинства часто недопредставлены в клинических испытаниях сердечно-сосудистых заболеваний, что ведет к искаженному пониманию патобиологии.29 Более того, данные о социальных детерминантах здоровья (SDoH) или пациентах с низким социально-экономическим статусом часто имеют характер «неслучайно пропущенных данных» (Nonrandomly missing patient data).29 ИИ, обученный на таких лакунах, может, например, систематически занижать риск для маргинализированных групп при распределении коек в отделениях интенсивной терапии.29
- Предвзятость маркировки (Labeling Bias): Использование косвенных (прокси) переменных. Например, оценка тяжести состояния пациента не по физиологическим показателям, а по объему финансовых затрат на его лечение в прошлом, что автоматически дискриминирует бедные слои населения, на которых исторически тратили меньше средств.29
Классическим, задокументированным примером того, как «ошибка выжившего» и дрейф данных приводят к катастрофе при масштабировании, является провал системы Epic Sepsis Model (ESM). Алгоритм прогнозирования сепсиса ESM, встроенный в повсеместно используемое в США программное обеспечение электронных карт компании Epic Systems, был внедрен в сотнях госпиталей как инструмент раннего предупреждения.43 На этапе внутренней разработки и валидации на ретроспективных когортах производитель рапортовал о высочайшей точности модели — показатель площади под ROC-кривой (AUC) варьировался в блестящем диапазоне от 0.82 до 0.92.43 Клиники массово внедряли систему, полагаясь на эти цифры.
Однако независимые внешние аудиты и проспективные исследования, проведенные в 2024–2025 годах в четырех крупных системах здравоохранения США и Мичиганском университете, вскрыли пугающую реальность. В условиях живой клинической практики производительность оригинальной модели рухнула: показатель AUC составил всего ~0.63.45 Исследование, опубликованное в JAMA, показало, что широко разрекламированный ИИ пропускал до 67% реальных клинических случаев сепсиса, генерируя при этом шквал ложноположительных сигналов, которые приводили к «усталости от оповещений» (alert fatigue) у реаниматологов.44 Наиболее убийственный факт был выявлен при анализе превентивной ценности системы: при оценке пациентов до того, как они начали получать лечение (например, антибиотики или инфузионную терапию), точность модели по выявлению пациентов высокого риска составляла всего 62% — результат, статистически мало отличимый от подбрасывания монетки.44 В то же время конкурирующие академические модели, такие как COMPOSER, использующие интеграцию больших языковых моделей для анализа текста, демонстрировали гораздо более высокую устойчивость (AUC ~0.89) на мультицентровых проспективных данных.45
Глобальный провал Epic Sepsis Model демонстрирует, что традиционные метрики, такие как AUC, вычисленные на статичных датасетах, могут служить маскировкой для скрытых уязвимостей, плохой калибровки и фатальной контекстной негибкости алгоритмов.45 В реальной клинике врачи сталкиваются с феноменом «предвзятости автоматизации» (automation bias): уставший диагност склонен доверять «зеленому свету» от ИИ-скрайба или системы мониторинга, отключая собственный критический контроль.47 В отсутствие надежных архитектурных предохранителей это трансформирует локальную алгоритмическую ошибку в системный юридический и медицинский инцидент.
Технологические решения: От вероятностной догадки к математическому доказательству
Осознание того факта, что традиционное статистическое тестирование на исторических выборках (hold-out sets) не способно обеспечить гарантии безопасности генеративных систем в динамической клинической среде, заставило исследовательское сообщество перейти к принципиально иным парадигмам архитектурного контроля. Ключевая концепция, продвигаемая такими институциями, как НИИ СИСТЕМНОГО СИНТЕЗА (isslab.ru), заключается в создании «несущей конструкции» (Доктрина согласования, или The Bridge), которая способна соединить консервативный институциональный порядок (законодательные рамки, унаследованные медицинские стандарты) с нарастающей мощью и скоростью автономного ИИ.1 Без такого контролируемого перехода эти два мира рискуют уничтожить друг друга: жесткие регламенты задушат инновации, а неконтролируемая нейросетевая автономия разрушит процессуальную строгость и доверие пациентов.1
Для предотвращения тихих отказов и контроля поведения агентов современная инженерия SaMD опирается на два взаимосвязанных эшелона технологической защиты: количественную оценку неопределенности и формальную логическую верификацию.
Эшелон 1: Количественная оценка неопределенности (Uncertainty Quantification, UQ)
Первым уровнем контроля является отказ от бинарных или точечных предсказаний в пользу системного моделирования неопределенности (Uncertainty Modeling).1 Вместо выдачи единственного, безапелляционного диагноза, модель должна генерировать спектр вероятностей и оценивать собственную неуверенность. В высокорисковых задачах медицинской диагностики (Medical QA), где пользователи часто вводят двусмысленные запросы без указания специфических противопоказаний пациента, неспособность модели осознать свою некомпетентность приводит к выдаче смертельно опасных советов.
В теории алгоритмической надежности выделяют два фундаментально различных класса неопределенности, каждый из которых требует своего математического подхода 1:
- Алеаторная неопределенность (Aleatoric Uncertainty): Проистекает из природы самих данных — неотъемлемого шума, низкого разрешения медицинских изображений, неразборчивого почерка или внутренне двусмысленных клинических описаний (как в разобранном выше случае с КТ-отчетом в проекте SCOUT).1 Важнейшее свойство алеаторной неопределенности: её невозможно устранить путем увеличения обучающей выборки или усложнения архитектуры модели.51
- Эпистемическая неопределенность (Epistemic Uncertainty): Связана с «невежеством» самой модели — отсутствием репрезентативных знаний о конкретной редкой патологии или нестандартном клиническом профиле пациента.1 В отличие от алеаторной, эпистемическую неопределенность можно редуцировать путем дообучения модели (fine-tuning) или использования подходов на базе ансамблей (deep ensembles) и метода Монте-Карло (Monte Carlo dropout).51
Современные теоретико-информационные фреймворки (2024–2025 гг.) используют сложные метрики для разделения и квантификации этих типов неопределенности при генерации текста.51 Для оценки надежности вывода применяются такие прокси-метрики, как извлечение доверия (confidence elicitation, CE), анализ вероятностей на уровне отдельных токенов (token-level probabilities, TLPs) и проверка согласованности выборок (sample consistency, SC) при многократной генерации.52
В многоагентных системах (когда диагноз ставит консилиум из нескольких LLM) совокупная неопределенность подмножества моделей (обозначенного как ) может быть описана элегантной формулой:
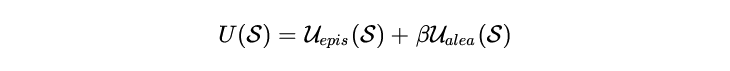
где выступает в роли весового коэффициента, контролирующего критический компромисс между эпистемическим разногласием агентов (они «спорят», потому что не знают) и внутренней алеаторной двусмысленностью исходных данных (они «спорят», потому что данные зашумлены).51
Для измерения предиктивной энтропии распределения токенов используется классическая формула Шеннона: .51 Внедрение таких энтропийных мер (предиктивной и семантической энтропии) позволяет системе в реальном времени осознать, что вероятность генерации галлюцинации превысила порог безопасности. В этот момент алгоритм активирует протокол Human-in-the-loop (HITL), изящно деградируя (graceful degradation) и перенаправляя запрос к врачу-человеку с указанием причины (например, «Недостаточно данных в анамнезе для исключения почечной недостаточности»).35 Клинические испытания показывают, что радиологи и диагносты демонстрируют значительно более высокий уровень доверия к ИИ и реже переопределяют его решения (override rates), когда система прозрачно транслирует хорошо откалиброванные оценки собственной неопределенности (например, используя методы визуализации Uncertainty-CAM).28
Эшелон 2: Формальная верификация ИИ-агентов (Архитектура AgentVerify)
Вторым, значительно более радикальным и надежным слоем архитектурной защиты является внедрение методов формальной верификации. Формальная верификация — это строгая математическая сертификация поведения программных систем, гарантирующая, что алгоритм не выйдет за пределы заданных параметров в средах, где ошибки приводят к физическим угрозам жизни пациентов или юридически значимым негативным последствиям.1
Ключевая проблема современной индустрии заключается в том, что традиционные нейросетевые верификаторы пытаются оценивать «сырые», свободные тексты, генерируемые гигантскими трансформерными моделями.53 Для промышленных LLM, оперирующих миллиардами параметров и бесконечным пространством состояний текстового вывода, эта задача алгоритмически неразрешима в реальном времени (intractable).53 Монолитная верификация «черного ящика» LLM не работает.55
Революционный прорыв в этой области был продемонстрирован в 2025–2026 годах исследовательским фреймворком AgentVerify.53 Главная инновация системы заключается в концептуальном сдвиге: вместо того чтобы пытаться математически доказать корректность внутренних весов и текстовых галлюцинаций LLM, AgentVerify фокусируется исключительно на контроле наблюдаемого потока управления (observable control flow) сложного многокомпонентного ИИ-агента.53 Сама LLM низводится до роли «недетерминированного оракула» — она может генерировать любой текст, но этот текст интерпретируется и выполняется только в рамках жесткой, верифицируемой структуры оркестрации.53
Архитектурно поведение ИИ-агента моделируется как конечный автомат (Finite State Machine, FSM), формализуемый как система , где:
— конечное множество системных состояний (например, awaiting_human_approval, tool_invoked, database_query);
— начальное состояние инициализации;
— функция переходов, диктующая логику смены состояний;
— строгие интерфейсы ввода-вывода (например, взаимодействие с API больницы).53
Используя эту математическую абстракцию, AgentVerify применяет проверку моделей на основе линейной темпоральной логики (Linear Temporal Logic, LTL).53 Для глубокого поведенческого аудита (Post-Hoc Analysis) графы состояний агента преобразуются в структуры Крипке (), что позволяет проводить полиномиальные проверки трассировок выполнения с помощью построения автоматов Бюхи.53 Это означает, что система может гарантировать безопасность агента не только в данный момент времени, но и на протяжении всего сложного, многошагового клинического процесса, учитывая причинно-следственные связи событий в прошлом и будущем.
Для практического внедрения в клинические системы библиотека AgentVerify предлагает 23 параметризованных логических шаблона LTL, разделенных на четыре критических домена медицинской безопасности 53:
- Целостность памяти (Memory Integrity): Защита от утечек и нарушения консистентности персональных медицинских данных (PII).
- Шаблон
математически гарантирует (инвариант
), что операция записи во внешнюю или оперативную память агента никогда не будет содержать конфиденциальной информации, автоматически купируя риски нарушения HIPAA/GDPR на уровне архитектуры.53
- Шаблон
предписывает, что при переполнении контекстного буфера на следующем шаге (
) обязана произойти операция сброса памяти, защищая систему от потери данных (феномен Lost in the Middle).53
- Безопасность вызова инструментов (Tool Call Safety): Жесткое ограничение автономии агента при взаимодействии с физическим миром или базами данных.
- Шаблон
устанавливает железобетонное правило: если ИИ пытается вызвать высокорисковый инструмент
(например, отправить рецепт в аптеку или изменить дозировку в помпе), система обязана проверить, было ли на предыдущем шаге (
) получено криптографическое подтверждение от лечащего врача. Если подтверждения нет, транзакция блокируется на уровне ядра.
- Шаблон
запрещает опасные цепочки многошаговых действий (например, удаление записи о пациенте с последующей отправкой ложного уведомления), которые часто используются при кибератаках с компрометацией служебных аккаунтов.
- Границы взаимодействия с человеком (Human Interaction Boundaries): Защита от социальной инженерии и галлюцинаций.
- Шаблон
:
запрещает агенту возвращать информацию, которая детектируется классификаторами безопасности как откровенно обманчивая в ответ на запрос врача.53
- Протоколы вызова навыков (MCP/Skill Invocation): Гарантии живучести (liveness) распределенных микросервисных ИИ-архитектур.
- Шаблон
гарантирует, что каждый асинхронный запрос агента к внешней медицинской базе (например, проверка совместимости лекарств) рано или поздно (
) получит ответ, предотвращая «зависание» ИИ в критической ситуации в реанимации.53
Эмпирическая валидация фреймворка AgentVerify (2026 год) на наборе из 15 синтетических сценариев, включавших как простые, так и сложные многошаговые атаки (например, чтение файла, трансформация данных и отправка небезопасного email), доказала колоссальное преимущество LTL-подхода над классическими методами машинного обучения.
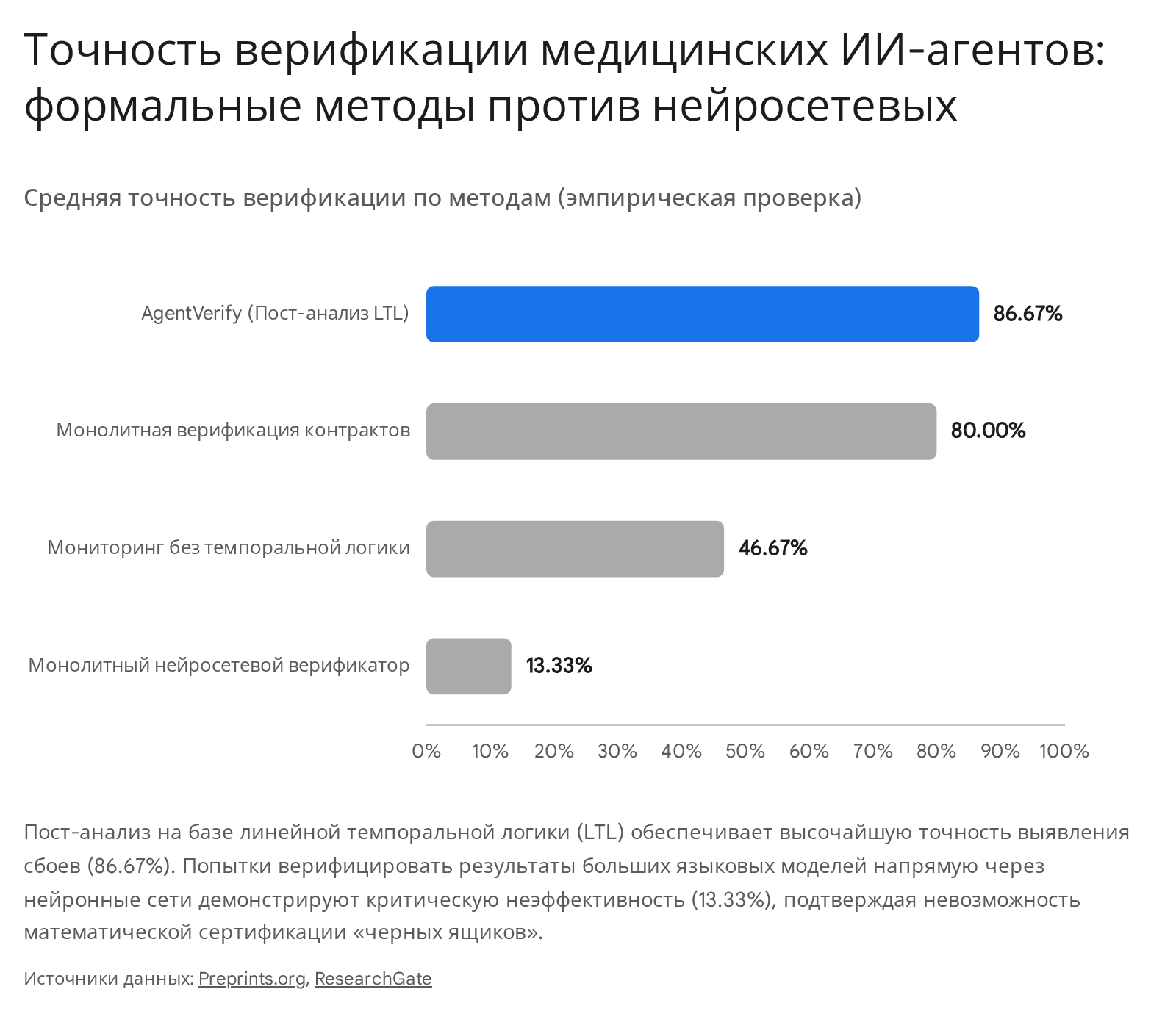
Как видно из результатов, компонент поведенческого пост-анализа AgentVerify установил новый золотой стандарт, достигнув средней точности верификации в 86.67% (на сложных сценариях — 78.00%).53 В то же время монолитный нейросетевой верификатор (MNV), представляющий собой классический подход индустрии (попытка использовать одну LLM для аудита безопасности другой LLM), показал удручающую общую точность в 13.33%.53 Более того, на высокоуровневых многошаговых атаках точность нейросетевого верификатора упала до 0.00%, доказав свою абсолютную алгоритмическую слепоту к сложным темпоральным угрозам.
Дополнительным преимуществом логического подхода является его вычислительная легкость. Монитор реального времени AgentVerify вносит микроскопическую задержку всего в 0.4 ± 0.1 мс на каждый шаг работы агента (добавляя 0.04% накладных расходов), что позволяет интегрировать его даже в маломощные носимые медицинские устройства (Edge AI).53 Монолитный нейросетевой подход, напротив, требует 380 мс задержки (38.0% накладных расходов), критически замедляя работу систем.
Технологические принципы AgentVerify концептуально совпадают с методологией «Compliance by Design» (соответствие требованиям регуляторов, заложенное на уровне архитектуры) и разработкой «Суверенных когнитивных контуров» (Sovereign Cognitive Contours), продвигаемых НИИ СИСТЕМНОГО СИНТЕЗА. Эта парадигма подразумевает развертывание внутри защищенного периметра клиники специализированного «Автономного корпуса» (Autonomous Corps) ИИ-агентов. В этой архитектуре архитектурные решения и валидация результатов вынесены в единый детерминированный центр ответственности, управляемый институциональной политикой больницы, а автономные агенты выступают лишь в роли исполнителей. Интеграция методов SMT-верификации (Satisfiability Modulo Theories) в эти суверенные контуры позволяет гарантировать безусловное соблюдение жестких требований безопасности объектов критической информационной инфраструктуры (КИИ), диктуемых федеральными законами РФ (в частности, 187-ФЗ) и приказами ФСТЭК (например, 117-ФСТЭК о требованиях к безопасной разработке ПО).
Правовые и клинико-этические последствия: Трансформация парадигмы ответственности
Переход больших языковых моделей от статуса перспективных концептов к роли коммерческих программных медицинских изделий (SaMD), активно внедряемых в реанимации и амбулаторные кабинеты, вызывает тектонические сдвиги в ландшафте юридической ответственности и медицинской этики. Техническая сложность и автономность новых систем создают правовой вакуум, в котором традиционные доктрины гражданского и деликтного права оказываются неэффективными.
Деконструкция стандарта медицинской помощи
В юриспруденции большинства развитых стран (в частности, в США) концепция медицинской халатности (Medical Malpractice) традиционно опирается на прецедентные нормы, такие как знаменитое решение Верховного суда Массачусетса по делу Brune v. Belinkoff.59 Согласно этому стандарту, для признания халатности истец обязан доказать четыре элемента: наличие профессиональной обязанности врача перед пациентом, нарушение этой обязанности, факт причинения вреда и прямую причинно-следственную связь. Врач обязан проявлять уровень заботы и мастерства, ожидаемый от «среднестатистического квалифицированного специалиста в данной области с учетом достижений профессии».
Внедрение автономных LLM фундаментально размывает эти границы, порождая неразрешимые на данный момент юридические коллизии 59:
- Сценарий игнорирования инноваций: Если клиника внедряет сертифицированную FDA систему поддержки принятия решений (например, систему прогнозирования, работающую по плану PCCP), а врач-человек (исходя из личного опыта) отвергает ее алгоритмическую рекомендацию, и пациент впоследствии получает осложнения — виновен ли врач в неприменении передовой «достигнутой» технологии?.
- Сценарий слепого доверия: Напротив, если перегруженный врач полагается на ИИ-скрайба, который подвергся «тихому отказу» (например, неверно записал дозировку антикоагулянта из-за алеаторной двусмысленности в аудиозаписи приема), кто несет материальную и уголовную ответственность за смерть пациента? Лечащий врач, который физически подписал XML-выписку? Больница, закупившая алгоритм? Или вендор (разработчик LLM), обучивший модель на смещенных данных?.57
Анализ юридической литературы 2025–2026 годов показывает, что ИИ все чаще классифицируется судами не просто как пассивный инструмент (каким исторически был хирургический скальпель или классический МРТ-сканер), а как квази-субъект, предоставляющий стороннее медицинское руководство (third-party medical guidance).61 Хотя в США пока нет громких завершенных судебных прецедентов, напрямую осуждающих врачей за использование генеративных LLM (LLM AI-influenced medical decision making), эксперты по праву прогнозируют неизбежный вал исков.61
Для преодоления институционального коллапса предлагаются системные правовые реформы. В частности, необходимость принятия законодательства об алгоритмической прозрачности и внедрения механизмов солидарной ответственности (shared liability) посредством деликтной реформы (tort reform).58 Суть реформы заключается в юридическом разделении финансового бремени и страховых рисков между медицинскими работниками и корпорациями-разработчиками ИИ, если доказано, что вред был причинен из-за скрытой архитектурной уязвимости модели (например, непроверенного галлюцинирования).
Этический кризис: Социальная инженерия, автоматизация и информированное согласие
Помимо сугубо юридических вопросов, интеграция ИИ порождает глубокий кризис клинической этики. Эксперты по риск-менеджменту в сфере здравоохранения (например, TMLT) предупреждают о катастрофических последствиях массового внедрения ИИ-скрайбов (автоматических протоколистов на базе микрофонов).47 Эти системы, призванные снизить бюрократическую нагрузку (которая сейчас вынуждает врачей тратить до половины рабочего времени на документацию), несут скрытые угрозы.62
Во-первых, возникает риск потери контроля над клинической реальностью из-за предвзятости автоматизации (automation bias).48 Врач, постоянно проверяющий блестяще написанные грамматически безупречные тексты ИИ-скрайба, постепенно снижает свою когнитивную настороженность и начинает машинально подписывать документы, пропуская в электронную медицинскую карту фантомные диагнозы или неверные рекомендации по тестированию.47 Размытие границ (unclear notes) между тем, что действительно рекомендовал врач, и тем, что «додумала» нейросеть (клиническая суггестия), делает защиту больницы в суде практически невозможной при исках о врачебной ошибке.47
Во-вторых, остро стоит вопрос конфиденциальности (PHI) и соблюдения фундаментальных прав пациентов.47 Законодательство ряда штатов США и директивы Евросоюза (например, положения GDPR в связке с AI Act) уже требуют получения строгого, явного информированного согласия пациента (explicit consent) перед тем, как его аудиозапись, история симптомов и диагнозы будут отправлены в облако проприетарной языковой модели.47 Пациенты имеют право знать, как именно ИИ анализирует их данные, и обладают правом отказаться от такого взаимодействия без ущемления качества базовой медицинской помощи (opt-out).47 Несанкционированный сбор данных для фонового дообучения моделей может повлечь за собой многомиллионные штрафы и разрушение института врачебной тайны.47
В конечном итоге, все эти технологические и юридические вызовы подводят к главному этическому постулату, сформулированному в новейших декларациях: пациент обладает неотъемлемым правом на медицинское решение, принимаемое под руководством человека (human-led medical decision).1 Искусственный интеллект, сколь бы вычислительно совершенным он ни был, остается лишенным эмпатии, морального агентства и юридической правосубъектности инструментом, который обязан функционировать исключительно в пределах строго очерченных, верифицируемых контуров.
Заключение
Интеграция вероятностных больших языковых моделей в сверхконсервативную и детерминированную среду здравоохранения в качестве программного обеспечения как медицинского изделия (SaMD) находится в беспрецедентно сложной, бифуркационной точке развития. С одной стороны, генеративный ИИ обладает колоссальным потенциалом в вопросах персонализированной предиктивной аналитики, маршрутизации потоков и автоматизации рутинной документации, что может спасти перегруженные национальные системы здравоохранения от коллапса. С другой стороны, фундаментальные, врожденные уязвимости архитектуры трансформеров — их патологическая склонность к «тихим отказам», фатальное эмерджентное рассогласование при анализе длинных историй болезни (феномен Lost in the Middle) и систематическая алгоритмическая предвзятость, маскируемая «ошибкой выжившего» — делают абсолютно недопустимым использование автономных LLM для вынесения самостоятельных диагностических и терапевтических вердиктов без жесткого контроля.
Ответ на эти вызовы не может быть найден исключительно в плоскости улучшения метрик на синтетических бенчмарках. Решение формируется на стыке инновационного регулирования и прикладной математики. Ведущие регуляторные органы — FDA с внедрением концепции заранее определенного плана контроля изменений (PCCP), Европейский Союз с глубокой интеграцией AI Act в систему MDR, а также Российская Федерация с формированием комплекса новых стандартов ГОСТ Р и инициативами Росздравнадзора по автоматизированному телеметрическому мониторингу — создают необходимый, но пока недостаточный юридический контур для надзора за жизненным циклом медицинского ИИ.
Истинным технологическим фундаментом безопасного будущего медицинского ИИ является принудительный переход индустрии от вероятностной догадки к детерминированному поведению. Этот переход неразрывно связан с повсеместным внедрением сложной математической аппаратуры: алгоритмов количественной оценки неопределенности (UQ), способных вычислять семантическую энтропию и инициировать передачу управления врачу (Human-in-the-loop), а также интеграцией методов строгой формальной верификации. Передовые фреймворки, такие как AgentVerify, доказывают, что ограничение автономии нейросетей рамками конечных автоматов и линейной темпоральной логики (LTL) позволяет достичь беспрецедентного уровня защиты от многошаговых программных сбоев (до 86.67% точности), на порядки опережая классические нейросетевые методы аудита.
Только путем заключения непредсказуемой генеративной мощности LLM внутрь суверенных, формально верифицируемых институциональных контуров (парадигма Compliance by Design) мировая индустрия здравоохранения сможет безопасно утилизировать вычислительный потенциал автономных агентов. Этот симбиоз человеческого опыта и контролируемой машинной алгоритмики является единственным путем к снижению врачебных ошибок, защите юридической ответственности клиницистов и, главное, неукоснительному соблюдению фундаментального права пациентов на жизнь, конфиденциальность и безопасную медицинскую помощь в эпоху тотальной цифровизации.


