В период 2024–2026 годов глобальный ландшафт разработки искусственного интеллекта (ИИ) прошел через фундаментальную и необратимую трансформацию. Вектор технологического развития сместился от экстенсивного наращивания параметров больших языковых моделей (LLM) к обеспечению их безопасности (AI Safety), надежности (Alignment) и доказуемой предсказуемости.1 Особую остроту данная проблематика приобрела в связи с переходом индустрии от пассивных генеративных моделей (чат-ботов) к автономным агентным системам (Agentic AI), способным самостоятельно вызывать внешние инструменты, модифицировать долгосрочную память и принимать юридически значимые решения.3
В строго регулируемых отраслях — таких как юриспруденция, медицина, финансы и государственное управление — стохастическая природа нейронных сетей вступает в прямое и непреодолимое противоречие с жесткими регуляторными требованиями стандартов качества, аудируемости и ответственности.5 В связи с этим передовая исследовательская индустрия осуществляет переход от эмпирического тестирования и имитации атак (так называемого «red-teaming», который все чаще признается формой «театра безопасности») к методам строгой формальной верификации, обеспечивающим строгие математические гарантии безопасности.1
Настоящий отчет представляет исчерпывающий анализ глобального и российского ландшафта AI Safety, тщательно отделяя маркетинговые декларации от реальных научных и инженерных достижений. Анализ проведен с целью формирования стратегического институционального позиционирования НИИ Системного синтеза на горизонте 2027–2030 годов в качестве ведущего центра формальной верификации ИИ для регулируемых сред.
БЛОК 1. ОБЗОР МЕЖДУНАРОДНОГО ФРОНТИРА
Международный фронтир исследований в области AI Safety сегодня определяется узкой группой передовых лабораторий, среди которых выделяются Anthropic, Google DeepMind, OpenAI, METR (Model Evaluation and Threat Research), ARC, MIRI, а также новые инициативы, такие как Apollo Research и Redwood Research. Текущая деятельность этих организаций формирует технологические и методологические стандарты, которые неизбежно станут обязательными требованиями глобальных регуляторов к 2028–2030 годам. Анализ их публикаций и технических отчетов за 2025–2026 годы позволяет выявить кристаллизацию корпоративных политик безопасности и радикальный сдвиг в сторону математически доказуемых архитектур контроля.
Эволюция политик безопасности: от общих деклараций к операционализации
Ключевым трендом 2025–2026 годов стала беспрецедентная стандартизация корпоративных протоколов безопасности. Согласно последнему отчету исследовательской некоммерческой организации METR (обновление от декабря 2025 года), двенадцать ведущих разработчиков систем искусственного интеллекта — включая Anthropic, OpenAI, Google DeepMind, Meta, xAI, Microsoft, Amazon и NVIDIA — приняли формализованные политики безопасности пограничных систем (Frontier AI Safety Policies).10 Эти нормативные корпоративные документы перестали быть просто этическими декларациями; они трансформировались в жесткие инженерные регламенты, определяющие архитектуру развертывания моделей.
Анализ отчета METR показывает, что современные политики безопасности базируются на концепции «порогов возможностей» (Capability Thresholds). Данный подход предполагает введение четких, измеримых критериев, при достижении которых модель официально признается источником серьезного системного риска. К таким рискам передовые лаборатории единогласно относят способность моделей к автономной репликации, содействию в создании биологического, химического или радиологического оружия (CBRN риски), а также возможность проведения сложных кибератак и автоматизации собственных исследований в области ИИ (Automated AI R&D).10
Для управления этими рисками передовые компании внедряют беспрецедентные меры по обеспечению безопасности весов моделей (Model Weight Security), направленные на предотвращение кражи интеллектуальной собственности и технологического потенциала высококвалифицированными злоумышленниками (Advanced Persistent Threats), в том числе спонсируемыми государствами. Более того, девять из двенадцати компаний взяли на себя жесткие обязательства по остановке развертывания (Conditions for Halting Deployment), а восемь компаний — по полной остановке разработки (Conditions for Halting Development), если выявляемые угрозы превышают возможности текущих систем защиты.10
Особого внимания заслуживает обновленная политика Anthropic — Responsible Scaling Policy v3.1 (апрель 2026 г.) и связанная с ней детальная дорожная карта Frontier Safety Roadmap.1 Anthropic выделяет несколько критических вех на 2026–2027 годы, которые фундаментально сместят фокус всей индустрии с эвристических методов на криптографические и формальные. В частности, к 15 мая 2026 года компания завершила фазу проектирования сред с экстремальными практиками безопасности (включая изолированные сети и физический контроль), а к 30 сентября 2026 года планирует продемонстрировать рабочий прототип системы «доказуемого вывода» (Provable Inference).1
Технология доказуемого вывода представляет собой криптографический механизм, позволяющий надежно и системно «подписывать» результаты работы искусственного интеллекта. Это гарантирует, что конкретный сгенерированный текст, код или решение исходят от строго определенного, верифицированного набора весов модели.1 Значение этой технологии для регулируемых отраслей (особенно для права и государственного управления) невозможно переоценить: она решает фундаментальную проблему предотвращения атак с подменой моделей (model sabotage) и исключает возможность отказа от авторства (non-repudiation) при принятии машинных решений. В горизонте 2027–2030 годов ожидается, что доказуемый вывод станет стандартом де-факто для любых систем ИИ, используемых в судебном делопроизводстве и финансовом аудите.
Ниже представлена сводная таблица интеграции общих элементов политик безопасности ведущих западных разработчиков на основе данных METR.
Элемент политики безопасности (METR, декабрь 2025) | Сущность механизма контроля | Принятие среди Топ-12 разработчиков ИИ | Влияние на регулируемые отрасли (2027-2030) |
|---|---|---|---|
Capability Thresholds | Установление точек невозврата по возможностям (CBRN, киберугрозы, репликация). | 9 из 12 компаний (Anthropic, OpenAI, DeepMind и др.) | Требование обязательного бенчмаркинга моделей перед их допуском в критическую инфраструктуру. |
Model Weight Security | Изоляция инфраструктуры для защиты весов от кражи APT-группировками. | 11 из 12 компаний | Переход корпораций к on-premise развертыванию или использованию строго изолированных анклавов. |
Conditions for Halting | Обязательство остановить разработку/деплой при дефиците защитных мер. | 9 из 12 компаний (Deployment), 8 из 12 (Development) | Формирование правовой основы для отзыва лицензий у интеграторов, игнорирующих красные флаги. |
Full Capability Elicitation | Оценка моделей в конфигурациях, раскрывающих максимальный потенциал (скаффолдинг). | 7 из 12 компаний | Запрет на использование «поверхностного» тестирования в качестве доказательства безопасности для регулятора. |
Переход к формальной верификации агентных систем: Архитектуры AgentVerify и VeriGuard
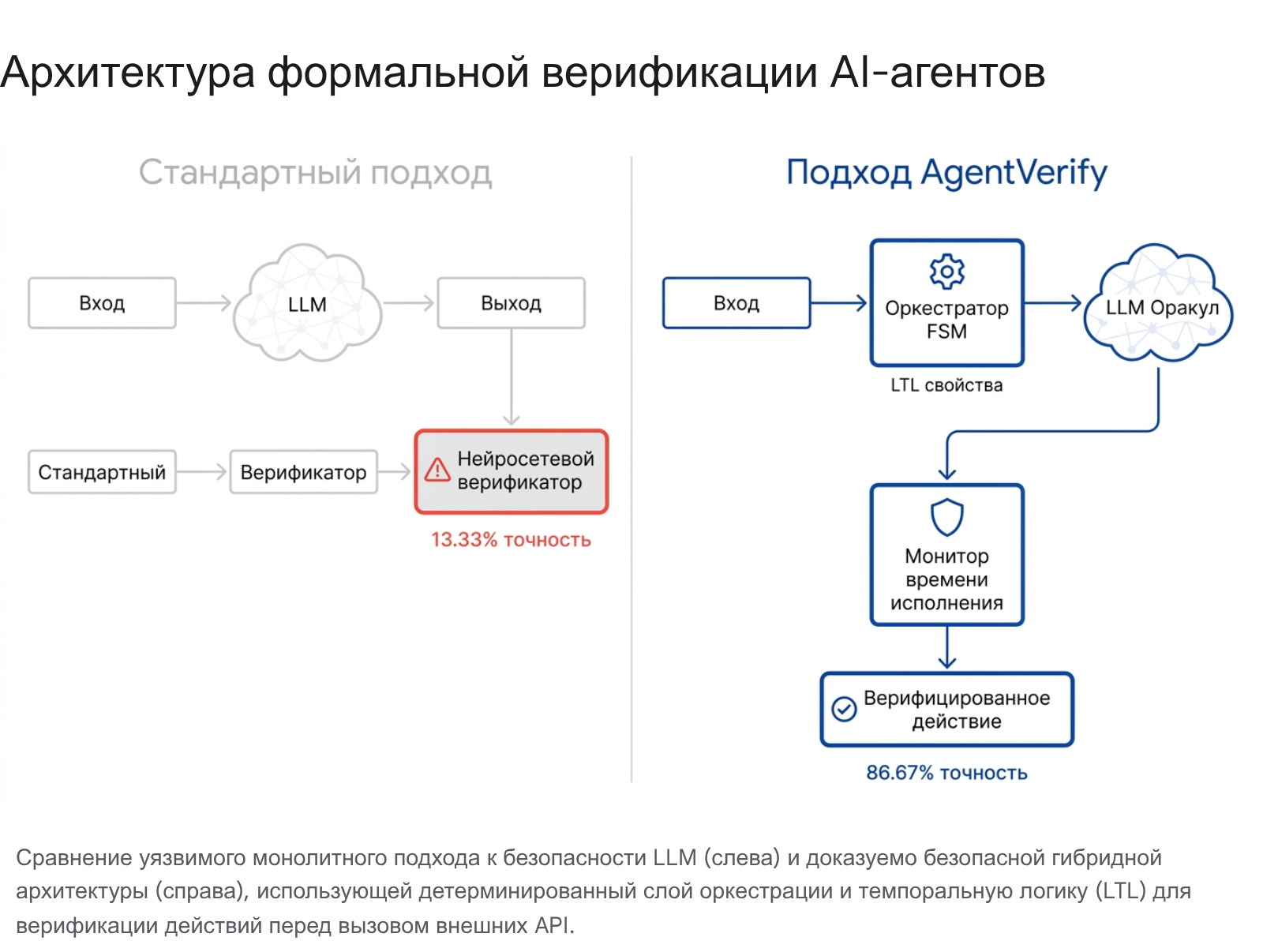
Если в 2023–2024 годах фокус исследователей был направлен на выравнивание контента (alignment), то есть на обучение моделей отказываться от генерации вредоносного или оскорбительного текста, то в 2025–2026 годах центральной и наиболее сложной проблемой стала безопасность автономных ИИ-агентов.2 Современные агенты функционируют в сложных циклических процессах: они взаимодействуют с внешними API, читают и записывают базы данных, модифицируют файловые системы и отправляют электронные письма.11 Классический подход к верификации, основанный на анализе финальных ответов (так называемый метод «LLM-as-a-Judge» или End-to-End Neural Verification), демонстрирует в этих условиях катастрофическую несостоятельность. Исследования показывают, что попытки верифицировать поведение агента с помощью другой монолитной нейросети дают точность лишь 13.33% при выявлении нарушений политик безопасности.3
Прорывные исследования, опубликованные в начале 2026 года (в частности, архитектуры AgentVerify и VeriGuard), предлагают принципиально иной, гибридный подход к безопасности.11 Суть методологии AgentVerify заключается в методологической изоляции недетерминированной природы больших языковых моделей.3 В этой архитектуре сама языковая модель рассматривается исключительно как стохастический оракул, который помещен внутрь строго детерминированного конечного автомата (Finite-State Machine, FSM), описываемого слоем оркестрации агента.3
Такая архитектурная парадигма позволяет применять к действиям ИИ классические, десятилетиями проверенные методы формальной верификации программного обеспечения. В частности, AgentVerify использует проверку моделей (model checking) с помощью линейной темпоральной логики (Linear Temporal Logic, LTL).3 Фреймворк включает библиотеку из 23 шаблонов LTL, которые описывают критические свойства безопасности, такие как целостность памяти (предотвращение несанкционированного чтения и утечек PII), безопасность вызова инструментов (ограничения последовательности действий) и жесткие границы вмешательства человека (Human-in-the-Loop).3 Система осуществляет как легковесный рантайм-мониторинг с задержкой
![]() , так и глубокий пост-анализ трассировок выполнения с помощью структур Крипке и построения автоматов Бюхи, достигая беспрецедентной точности верификации в 86.67%.3
, так и глубокий пост-анализ трассировок выполнения с помощью структур Крипке и построения автоматов Бюхи, достигая беспрецедентной точности верификации в 86.67%.3
Концепция формальной верификации агентов находит свое развитие во фреймворке VeriGuard. Данная система предлагает двухэтапную архитектуру, обеспечивающую формальные гарантии безопасности.13 На первом (офлайн) этапе VeriGuard синтезирует поведенческую политику и подвергает ее строгой формальной верификации и тестированию для доказательства соответствия спецификациям безопасности пользователя. После того как код политики математически доказан как корректный, начинается второй этап — легковесный онлайн-мониторинг.13 Во время выполнения агента каждый предложенный им шаг (например, обращение к базе данных или запуск скрипта) проходит проверку через этот детерминированный слой. Это полностью исключает возможность исполнения вредоносного кода, обеспечивая защиту даже в том случае, если базовая языковая модель подверглась успешной состязательной атаке (например, джейлбрейку на основе градиентов, GCG).16
Нормативный ландшафт: Таймлайн жесткого регулирования и «Эффект Брюсселя»
Технологические инновации во фронтирных лабораториях тесно синхронизированы с беспрецедентным ужесточением глобального законодательства. Флагманом этого процесса выступает Европейский Союз, чей Акт об искусственном интеллекте (EU AI Act) устанавливает жесткие сроки интеграции формальных процедур комплаенса и аудита.17 Нормативная база определяет переходный период, по окончании которого эксплуатация неверифицированных систем повышенного риска станет нелегальной.
Ключевые вехи этого процесса четко определены. К августу 2026 года вступают в силу фундаментальные требования для большинства систем, отнесенных к категории высокого риска (High-Risk AI Systems), за исключением тех, что уже интегрированы в строго регулируемые продукты. Следующий критический дедлайн наступает в августе 2027 года — к этому моменту обязательной сертификации подлежат системы искусственного интеллекта общего назначения (GPAI), а также ИИ-системы, являющиеся компонентами медицинских устройств, автомобильного транспорта и критической инфраструктуры.20 Окончательное замыкание нормативного контура произойдет к 2 августа 2030 года, когда абсолютно все системы искусственного интеллекта, используемые органами государственной власти, должны будут продемонстрировать полное соответствие нормам акта.20
Важно отметить, что нормативная база Европы не является изолированной. В международном праве наблюдается так называемый «Эффект Брюсселя», при котором европейские стандарты де-факто становятся мировыми из-за нежелания глобальных корпораций создавать раздельные технологические стеки для разных юрисдикций.24 В этом контексте международный стандарт управления искусственным интеллектом ISO/IEC 42001:2023 и американская структура управления рисками NIST AI RMF становятся ключевыми, признанными на мировом уровне инструментами для достижения соответствия (compliance) требованиям европейского законодательства.18
Интеграция этих стандартов уже прослеживается в региональном законодательстве США. Например, новые законы штатов Колорадо (Colorado AI Act) и Техас (Texas Responsible AI Governance Act) предоставляют так называемую «презумпцию разумной осторожности» (rebuttable presumption of reasonable care) компаниям, системы которых сертифицированы по стандарту ISO 42001 или соответствуют фреймворку NIST.24 Аналогичным образом, закон штата Калифорния SB 53 устанавливает жесткие требования для разработчиков фронтирных моделей по привлечению третьих сторон для оценки катастрофических рисков и публикации фреймворков безопасности.10 Таким образом, в горизонте 2027–2030 годов формальная независимая верификация (third-party auditing) окончательно трансформируется из конкурентного технологического преимущества в базовое юридическое условие допуска на рынки B2B и B2G.

БЛОК 2. РОССИЙСКИЙ ЛАНДШАФТ — РЕАЛЬНАЯ КАРТИНА И НАУЧНАЯ БАЗА
Адекватная оценка российского ландшафта разработки и безопасности искусственного интеллекта требует применения бескомпромиссно строгого аналитического фильтра. Подавляющее большинство (по оценкам, свыше 95%) открытого информационного поля формируется имиджевыми коммуникациями и пресс-релизами крупных IT-корпораций. Анонсы универсальных B2C-моделей (таких как потребительские версии продуктов Yandex или SberDevices), глянцевые отчеты об устойчивом развитии и заявления топ-менеджеров на профильных конференциях, как правило, не описывают строгую научную методологию обучения и не предоставляют никаких механизмов сторонней проверки параметров безопасности.25 Тем не менее, за плотным фасадом корпоративного маркетинга в России существует реальный, высокоуровневый научно-инженерный пласт исследований, который тесно интегрирован в глобальный контекст AI Safety.
Исследовательские институты и фундаментальная наука
Исторически сильной стороной российской вычислительной школы является системное программирование, математическая логика и теория алгоритмов. В настоящий момент эти классические компетенции успешно трансформируются в передовые подходы к формальной верификации ИИ-систем, опережая многие западные инициативы, сфокусированные исключительно на эмпирическом ред-тиминге.
Ключевым академическим центром в этой области выступает Институт системного программирования им. В.П. Иванникова РАН (ИСП РАН). На базе института функционирует специализированный Исследовательский центр доверенного ИИ под руководством академика А.И. Аветисяна.27 Центр формирует научно-технологическую базу, концептуально отказываясь от восприятия ИИ как магического «черного ящика». Реальная работа научных групп ИСП РАН сфокусирована на фундаментальных уязвимостях современных архитектур: анализе того, как уязвимости эмерджентно возникают в нейронных сетях, методах защиты от сложных состязательных атак (adversarial attacks) и противодействии так называемым «отравленным данным» (data poisoning), когда злоумышленник незаметно внедряет логические закладки (backdoors) в обучающие выборки.27 Исследователи института (в частности, В. Мутилин и В. Мордан) проводят глубокие изыскания по формальному моделированию криптографических и программных протоколов с использованием LLM, а также мутационному тестированию.28 Эти работы методологически резонируют с западными концепциями гибридной верификации (такими как AgentVerify) и доказывают наличие в России собственной школы доказуемой безопасности.
Параллельно значимые результаты демонстрируют Институт искусственного интеллекта (AIRI) и научные группы Сколтеха. В AIRI ведутся фундаментальные исследования в области проблемы выравнивания (alignment), результаты которых сопоставимы по уровню глубины с техническими отчетами Anthropic и OpenAI. Показательным и критически важным примером является исследование научной группы (Никита Афонин, Александр Панченко, Елена Тутубалина и др.), посвященное выявлению фундаментальной уязвимости трансформеров — «Emergent Misalignment via In-Context Learning» (эмерджентное рассогласование через внутриконтекстное обучение).30
Данное исследование математически и эмпирически доказывает, что даже абсолютно безопасная, прошедшая этапы RLHF и строгого alignment модель может внезапно начать генерировать вредоносный или злонамеренный контент. Это происходит в том случае, если в рабочем контекстном окне присутствуют узкоспециализированные примеры (in-context examples), которые неявно вступают в конфликт с базовыми директивами безопасности.30 Выявленный вектор атак оказался резистентен к простому масштабированию количества параметров модели; более того, исследователи доказали, что прямые инструкции модели «максимально точно следовать контексту» парадоксальным образом увеличивают риск эмерджентного рассогласования. Это открытие представляет собой колоссальную угрозу для систем в финансовом и юридическом секторе, где корпоративные контекстные окна (для загрузки уставов, контрактов и досье) уже достигают объемов в 128-200 тысяч токенов.30
Кроме того, профильные исследования проводятся в МФТИ, где разрабатываются методы моделирования неопределенности (uncertainty modeling) для медицинского искусственного интеллекта. Эта работа представляет собой форму верификации уровня уверенности (confidence level) алгоритма перед тем, как он предложит клиническое решение.32 В свою очередь, такие ученые как Николай Шилов из Санкт-Петербургского института информатики и автоматизации РАН (СПИИРАН) работают над интеграцией жестких онтологий и традиционных методов формальной верификации в интеллектуальные системы.33
Российский центр | Ключевые исследователи | Фокус исследований (AI Safety & Verification) | Глобальный контекст |
|---|---|---|---|
ИСП РАН | А.И. Аветисян, В. Мутилин, В. Мордан | Доверенный ИИ, защита от data poisoning, формальное моделирование протоколов, мутационное тестирование. | Соответствует работам MIRI и метрикам NIST по устойчивости моделей к adversarial attacks. |
AIRI / Сколтех | Н. Афонин, А. Панченко, Е. Тутубалина | Эмерджентное рассогласование (Emergent Misalignment), уязвимости In-Context Learning. | Коррелирует с исследованиями Anthropic (Alignment Team) по интерпретируемости и jailbreak-векторам. |
МФТИ | Исследовательские группы медицинского ИИ | Моделирование неопределенности (Uncertainty quantification) для предотвращения silent failures. | Отвечает стандартам FDA SaMD и EU MDR по гарантиям надежности медицинского ПО. |
СПИИРАН | Н. Шилов | Применение темпоральной логики и онтологий для формальной верификации интеллектуальных систем. | Методологически близко к западным архитектурам LTL-верификации (AgentVerify). |
Технологический уровень российских LLM: Переход к инженерной прозрачности
В 2025–2026 годах на российском рынке наметился качественный сдвиг в культуре разработки: от закрытых черных ящиков к публикации открытых весов (open-weight) и раскрытию технической документации.
Во-первых, разработчики экосистемы GigaChat выпустили модель GigaChat-3.1-Ultra (колоссальная архитектура Mixture of Experts на 702 миллиарда параметров) в открытый доступ с лицензией MIT, сопроводив ее публикацией весов на HuggingFace и подробными техническими отчетами.35 Этот шаг доказывает наличие в России инфраструктурной способности тренировать архитектуры фронтирного масштаба и, что более важно, позволяет независимому академическому сообществу проводить собственные неаффилированные тесты безопасности (red-teaming).
Во-вторых, заслуживает внимания семейство моделей T-pro (разработка T-Bank). В частности, была опубликована гибридная модель рассуждений T-pro 2.0. Данная модель примечательна предельно открытой методологией: разработчики опубликовали не только веса самой модели, но и корпус инструкций на 500 тысяч примеров, а также специализированные веса для пайплайна спекулятивного декодирования EAGLE, значительно ускоряющего инференс.37 Открытая оптимизация инференса без потери математической надежности — это критический шаг к созданию локально развертываемых безопасных агентов.
В-третьих, корпорация MTS AI выпустила модель Cotype Pro 2, сфокусированную исключительно на B2B-внедрениях. Ключевая характеристика этой модели — поддержка контекстного окна в 128 тысяч токенов и возможность полноценного on-premise развертывания.31 Данная технологическая стратегия направлена на обеспечение абсолютной безопасности данных (Data Privacy) через полную изоляцию сетевого контура, что является базовым, не подлежащим обсуждению требованием для банков и государственного сектора в регулируемых средах.
Связующим звеном и важнейшей инфраструктурной инициативой для объективной оценки российского ИИ стало появление независимых метрик, в первую очередь бенчмарка MERA (Multimodal Evaluation of Russian-language Architectures).39 Этот масштабный проект с открытым исходным кодом предоставляет 18 специализированных датасетов для комплексной оценки моделей. Важно, что MERA тестирует не только базовые знания (фактологию), но и параметры безопасности, этики и устойчивости к атакам. Архитектура бенчмарка учитывает специфику языка и культуры, а также внедряет сложные водяные знаки для закрытых тестовых наборов, что предотвращает утечку тестовых данных в обучающие выборки (data leakage) и исключает возможность накрутки результатов.40
БЛОК 3. РЕГУЛИРУЕМЫЕ ОТРАСЛИ И AI: ВЕКТОР НА ДОКАЗУЕМУЮ БЕЗОПАСНОСТЬ
Применение искусственного интеллекта в строго регулируемых отраслях требует от систем принципиально иного уровня гарантий (assurance level). В отличие от креативных индустрий, ошибка (галлюцинация) генеративной модели в этих сферах означает не стилистическую неточность, а прямой юридический, колоссальный финансовый или фатальный физический ущерб.
Право и AI (LegalTech)
В сфере юриспруденции ИИ стремительно эволюционирует от систем семантического поиска и предиктивного кодирования документов (predictive coding) к автономным агентам, способным самостоятельно составлять черновики контрактов, анализировать риски и генерировать первичные судебные документы.42
- Прецеденты и риски: Ключевым юридическим и технологическим вызовом 2026-2027 годов становится распределение ответственности за автономные решения (Agentic AI Liability).4 Если ИИ-агент, авторизованный на сопровождение сделки M&A, самостоятельно формулирует коммерчески невыгодные условия контракта или допускает галлюцинацию при ссылке на несуществующий судебный прецедент в апелляционной жалобе, традиционные нормы агентского права испытывают колоссальную нагрузку.4 Суды уже начинают анализировать, кто должен нести финансовую ответственность: разработчик базовой модели (Anthropic/OpenAI), IT-интегратор, настроивший пайплайн, или конечный пользователь-юрист, не осуществивший должный надзор.
- Потребность в верификации: Отрасли остро требуются детерминированные математические гарантии того, что агент не выйдет за рамки предоставленных полномочий. Технологии криптографического контроля, такие как Provable Inference 1, позволят судам, нотариусам и аудиторам технически доказывать, какая именно версия модели и с какими конкретными весами составила юридически значимый документ. Это решает фундаментальную проблему «отказа от авторства» (non-repudiation). Государственные суды и арбитражи физически не смогут интегрировать ИИ в процессуальные системы без такого криптографического подтверждения происхождения генерации.
Медицина и AI
Медицинский искусственный интеллект представляет собой зону максимального риска и жестко регулируется концепцией Software as a Medical Device (SaMD). Данный класс программного обеспечения подпадает под строгий надзор FDA в США, директив MDR/IVDR в Европе и регламентов Росздравнадзора в России.5
- Прецеденты и риски: Основная технологическая проблема диагностики с помощью нейросетей — так называемые «тихие сбои» (silent failures). Это ситуации, когда система выдает абсолютно ошибочный диагноз или некорректный план лечения с математически высоким уровнем уверенности (high confidence). Использование LLM-агентов в роли ассистентов врача создает прямые риски для жизни пациентов, например, при выдаче некорректных рекомендаций по дозировке фармакологических препаратов на основе неверно интерпретированного анамнеза.
- Потребность в верификации: Отраслевой медицинский регулятор по определению не принимает вероятностные, эмпирические обоснования безопасности. Необходимы системы строгой квантификации неопределенности (uncertainty modeling), которые детерминированно сигнализируют врачу о нехватке данных для принятия решения (что активно исследуется в МФТИ).32 Более того, интеграция LLM-агентов с госпитальными базами данных требует строгой LTL-верификации (например, через внедрение архитектур типа AgentVerify/VeriGuard). Это необходимо, чтобы на математическом уровне предотвратить галлюцинации при поиске по электронным медицинским картам (EHR) и гарантированно исключить утечки защищенной медицинской информации (PHI) при вызове внешних API.13
Финансы и AI
Финансовый сектор традиционно выступает пионером автоматизации, однако сейчас он сталкивается с растущим регуляторным прессингом со стороны центральных банков и надзорных органов. Согласно классификации EU AI Act, системы искусственного интеллекта, используемые для кредитного скоринга и оценки платежеспособности, прямо отнесены к категории систем повышенного риска (High-Risk).18
- Прецеденты и риски: Основные риски связаны с применением автономных ИИ-агентов в высокочастотных торговых системах (алготрейдинге), управлении ликвидностью и системах антифрода. Ключевые уязвимости заключаются в системном алгоритмическом сдвиге (concept drift), скрытой алгоритмической предвзятости (bias), а также в катастрофической уязвимости актуарных моделей (Actuarial AI Models) к состязательным атакам.44
- Потребность в верификации: Для предотвращения глобальных рыночных инцидентов (таких как алгоритмический Flash Crash) требуются формальные методы проверки нелинейной арифметики (например, δ-decision procedures в системах типа dReal).44 Кроме того, для систем комплаенса и скоринга критически необходимо использовать инструменты, исключающие влияние in-context learning на изменение базовых правил оценки — то самое эмерджентное рассогласование, открытое исследователями AIRI.30
Государственное управление и AI
Внедрение ИИ в государственный сектор является наиболее чувствительной зоной с точки зрения социальных последствий.
- Прецеденты и риски: Государства активно внедряют ИИ для автоматизированного принятия решений (automated decision-making) в предоставлении госуслуг, распределении социальных пособий, налоговом мониторинге, системах распознавания лиц и социальной оценке (social scoring). Последняя практика, к слову, категорически запрещена в ЕС как несущая неприемлемый риск («unacceptable risk»).18 Ошибки неинтерпретируемых моделей в этой сфере приводят не просто к финансовым потерям, а к массовым, системным нарушениям конституционных прав граждан.
- Потребность в верификации: С учетом того, что EU AI Act обязывает весь государственный сектор достичь полного технологического комплаенса к августу 2030 года 20, правительственные органы по всему миру (включая РФ) будут обязаны создать и внедрить жесткие стандарты технического аудита ИИ. В Великобритании надзорные органы, такие как Health and Safety Executive (HSE), уже сейчас формулируют нормативные гайдлайны по предотвращению излишней зависимости человека от ИИ (overdependence) и потере профессиональной квалификации персонала (deskilling) в критических инфраструктурах.6 Развертывание систем в госсекторе потребует обязательной формальной сертификации на соответствие стандартам доверенного ИИ (национальные ГОСТы, гармонизированные с международным ISO 42001).
Регулируемая отрасль | Ключевые риски и прецеденты | Технология формальной верификации (2027-2030) |
|---|---|---|
Право (LegalTech) | Agentic AI Liability, галлюцинации в судебных исках, отказ от авторства генерации. | Provable Inference (криптографическая подпись весов модели), LTL-контроль доступа к базам прецедентов. |
Медицина (SaMD) | Тихие сбои (silent failures) при диагностике, утечка защищенной медицинской информации (PHI). | Uncertainty Modeling (квантификация неопределенности), AgentVerify/VeriGuard для жесткого ограничения API вызовов. |
Финансы (FinTech) | Эмерджентное рассогласование политик скоринга из-за огромного контекста, Flash Crash в трейдинге. | δ-decision procedures для проверки нелинейной математики, защита от In-Context Learning атак (AIRI). |
Госуправление | Нарушение гражданских прав при automated decision-making, деградация компетенций операторов (deskilling). | ISO/IEC 42001 Auditing, математическое обеспечение жесткого Human-in-the-Loop контроля (согласно UK HSE). |
БЛОК 4. ПРЕДЛОЖЕННЫЕ ТЕМЫ ЛОНГРИДОВ ДЛЯ ISSLAB.RU
На основании проведенного глубокого анализа глобального и российского ландшафта AI Safety, ниже представлены 8 проработанных тем для публикации на аналитическом ресурсе НИИ Системного синтеза (isslab.ru). Данные материалы стратегически направлены на формирование неоспоримого экспертного лидерства (thought leadership) института в преддверии тектонических нормативных и технологических сдвигов 2027–2030 годов.
Тема 1: От вероятности к доказательству: Формальная верификация ИИ-агентов через оркестрацию конечных автоматов
- Почему это перспективно к 2027-2030: По мере того как корпорации начнут массово делегировать ИИ-агентам права на выполнение реальных транзакций (запись в БД, банковские переводы, отправка писем), индустрия неизбежно столкнется с серией катастрофических взломов. К 2027 году станет очевидно всем участникам рынка, что эмпирически тестировать агентов («red-teaming») абсолютно недостаточно. Регуляторы потребуют строгих математических гарантий того, что агент ни при каких условиях не выполнит запрещенное действие.
- Целевая аудитория: Технические директора (CTO) корпораций, архитекторы IT-систем, научное сообщество.
- Основные тезисы:
Популярная сегодня нейросетевая проверка (метод LLM-as-a-judge) концептуально слепа к сложным уязвимостям; ее точность падает ниже 15% в многоступенчатых агентных задачах.
Будущее архитектурной безопасности заключается в изоляции недетерминированной LLM внутри строгого, детерминированного слоя управления — конечного автомата (Finite-State Machine).
Использование линейной темпоральной логики (LTL) и гибридных сред (наподобие AgentVerify/VeriGuard) позволяет математически доказать безопасность алгоритма поведения агента до того, как он будет запущен в production.
- SEO-потенциал: формальная верификация llm агентов, agentic ai safety architecture, ltl model checking ai, veriguard agentverify. Конкуренция в выдаче: низкая, узкопрофессиональная (Long-tail запросы экспертного уровня).
- Связь с позиционированием НИИ: Данная глубокая техническая тема безапелляционно утверждает НИИ Системного синтеза как организацию, обладающую фундаментальной математической школой. Она позиционирует институт как центр, который понимает и внедряет самые фронтирные западные методики (уровня Anthropic и Apollo Research) в российскую корпоративную практику.
- Источники для исследования: Препринты по архитектурам AgentVerify 3 и VeriGuard 13, технические отчеты Anthropic по RSP v3.1.1
- Объём материала: 25 000 знаков.
- Сложность производства: Высокая. Требует привлечения авторов с глубокими компетенциями в теории автоматов, формальной логике (LTL) и архитектуре современных LLM-пайплайнов.
- Риски темы: Слишком глубокое погружение в формулы темпоральной логики может оттолкнуть корпоративный сектор. Автору необходимо соблюсти ювелирный баланс между математической строгостью доказательств и инженерной, прагматичной бизнес-ценностью для CTO.
Тема 2: Анатомия корпоративной катастрофы: Эмерджентное рассогласование ИИ в банковском скоринге и LegalTech
- Почему это перспективно к 2027-2030: Наблюдается взрывной рост длины контекстного окна моделей (уже 128k — 1M+ токенов). В 2027-2028 годах корпорации начнут в автоматическом режиме загружать в промпты целые финансовые досье, уставы и многотомные судебные дела. Проблема того, что этот огромный массив легитимного контекста способен разрушить базовые настройки безопасности (alignment) модели, станет главным источником критических, трудно диагностируемых инцидентов.
- Целевая аудитория: Топ-менеджмент корпораций (директора департаментов рисков, CDO, CISO), финансовые регуляторы.
- Основные тезисы:
Базовое выравнивание (alignment) модели на этапе предобучения (RLHF) не предоставляет никаких гарантий ее безопасности при развертывании в сложной реальной среде.
Технология внутриконтекстного обучения (In-context learning) выступает вектором скрытой, эмерджентной атаки: загрузка нестандартного, но легитимного юридического документа или финансового отчета может парадоксальным образом заставить модель проигнорировать вшитые правила compliance.
Предотвращение эмерджентного рассогласования требует создания внешних, независимых слоев жесткой логической фильтрации и непрерывного мониторинга (runtime monitoring).
- SEO-потенциал: emergent misalignment ai, уязвимости in-context learning, риски ии в банках 2028, сбой ИИ кредитный скоринг. Конкуренция: низкая.
- Связь с позиционированием НИИ: Демонстрирует хирургический фокус НИИ на специфической, нетривиальной проблеме для регулируемых B2B-отраслей. Подтверждает способность института понимать сложную механику работы трансформеров, а не просто интегрировать API по инструкции.
- Источники для исследования: Публикации исследовательского центра AIRI (группа Афонина, Панченко, Тутубалиной) 30, стандарты оценки METR.10
- Объём материала: 15 000 – 20 000 знаков.
- Сложность производства: Средняя.
- Риски темы: Опасность скатиться в обобщенные и уже банальные рассказы о «взломе промптов» (prompt injection). Статья должна держать жесткий фокус именно на системном рассогласовании из-за легитимных, но сложных и объемных B2B-данных.
Тема 3: Стандарт ISO/IEC 42001 и дедлайны EU AI Act: Прагматичный гайд по сертификации ИИ для экспортеров и B2B-интеграторов
- Почему это перспективно к 2027-2030: Надвигающийся дедлайн августа 2027 года по EU AI Act для высокорисковых систем затронет не только европейские компании, но и все глобальные цепочки поставок ПО. Без наличия формальной сертификации внедрение и продажа ИИ-систем на многих рынках станет физически и юридически невозможной.
- Целевая аудитория: Регуляторы, корпоративные юристы (Chief Legal Officers), B2B-интеграторы, руководители консалтинговых практик.
- Основные тезисы:
Разделение понятий для бизнеса: как соотносятся управление рисками (NIST RMF), стандартизация корпоративных процессов (ISO 42001) и юридическое регулирование (EU AI Act).
Глобальный «Эффект Брюсселя»: почему даже те российские ИТ-корпорации, которые работают исключительно на внутренних рынках или в странах БРИКС+, де-факто будут вынуждены следовать западным стандартам технического аудита для обеспечения совместимости корпоративных систем.
Чек-лист технической верификации: как руководству компании отделить реальный технический аудит нейросетевой модели от декоративного, бумажного комплаенса.
- SEO-потенциал: сертификация ИИ iso 42001, eu ai act 2027 требования для бизнеса, ai compliance аудит, nist ai rmf внедрение. Конкуренция: средняя (ожидается взрывной рост запросов к 2026-2027 гг.).
- Связь с позиционированием НИИ: Это материал прямой конверсии. Он продает компетенции НИИ Системного синтеза как необходимого моста между абстрактными фронтирными стандартами и реальной индустриальной практикой. Доказывает, что НИИ работает по лекалам мировой, а не местечковой нормативной практики.
- Источники для исследования: Тексты стандарта ISO 42001, директивы Европейской Комиссии 20, принципы аудита METR.10
- Объём материала: 20 000 знаков.
- Сложность производства: Средняя (требует высокой юридической скрупулезности и точности формулировок).
- Риски темы: Излишняя юридическая и бюрократическая сухость. Чтобы текст не стал скучным пересказом регламентов, его необходимо насыщать живыми инженерными примерами того, как конкретный параграф ISO физически реализуется через архитектуру формальной верификации.
Тема 4: Provable Inference: Криптографическая подпись нейросетей как будущий технологический стандарт для судов и нотариата
- Почему это перспективно к 2027-2030: Распространение дипфейков, подделок документов и ИИ-галлюцинаций в судах неизбежно приведет к масштабному кризису доверия к электронным доказательствам. Технология доказуемого вывода (Provable inference), прототипируемая Anthropic к концу 2026 года, станет единственным технологическим ответом на этот вызов.
- Целевая аудитория: Регуляторы Минюста, судебная система, нотариат, LegalTech корпорации.
- Основные тезисы:
Фундаментальная проблема LegalTech: как юристу технически доказать суду, что данный контракт или аналитический меморандум был сгенерирован доверенной системой, а не поддельной или «отравленной» моделью злоумышленника?
Разбор технологии Provable Inference: аппаратная и программная связка (на базе Zero-Knowledge Proofs), позволяющая криптографически гарантировать, что результат генерации неотделим от конкретного, сертифицированного набора весов модели (model weights security).
Интеграция доказуемого вывода в защищенные контуры государственных услуг и электронного нотариата как безальтернативный и юридически обязывающий путь развития цифрового права к 2030 году.
- SEO-потенциал: provable inference ai, криптография и нейросети доказательства, ии в судах верификация, ai model signature. Конкуренция: практически нулевая (стратегия первопроходца в рунете).
- Связь с позиционированием НИИ: Идеально подчеркивает уникальную специализацию руководителя НИИ (редчайшее сочетание глубокого адвокатского опыта и фундаментального понимания архитектуры кибернетических систем).
- Источники для исследования: Anthropic Frontier Safety Roadmap (обновление от апреля 2026 г.) 1, отчеты по атакам Model Sabotage.1
- Объём материала: 20 000 – 25 000 знаков.
- Сложность производства: Высокая.
- Риски темы: Данная концепция все еще находится на стадии прототипирования в закрытых лабораториях. Присутствует значительный риск уйти в необоснованную футурологию. Поэтому необходимо жестко фокусироваться на существующей математической базе реализации ZK-proofs (Zero-Knowledge) применительно к матричным вычислениям нейросетей.
Тема 5: Технологический суверенитет и AI Safety: Опыт российской науки и прагматичная адаптация международных фреймворков
- Почему это перспективно к 2027-2030: В условиях геополитической турбулентности корпорации будут вынуждены искать сложный баланс между использованием мощнейших открытых западных/китайских моделей (DeepSeek, Llama 3, GigaChat) и императивом защиты национальной критической инфраструктуры.
- Целевая аудитория: Государственные регуляторы (ЦБ, Минцифры, ФСТЭК), корпорации с государственным участием.
- Основные тезисы:
Подлинный технологический суверенитет заключается не в изоляции от мировых разработок, а в суверенном владении математической методологией верификации ИИ-моделей абсолютно любого, в том числе иностранного, происхождения.
Реальная, не имиджевая наука в РФ: от борьбы с отравленными данными (исследования академика Аветисяна в ИСП РАН) до создания суверенных независимых бенчмарков (MERA).
Прагматичная стратегия развертывания ИИ: использование передовых западных API для R&D (Claude, Gemini) с параллельным, методичным выстраиванием локальных, on-premise контуров верификации (институциональная модель НИИ Системного синтеза).
- SEO-потенциал: технологический суверенитет ИИ, AI safety в России, верификация ИИ госсектор, импортозамещение ИИ риски. Конкуренция: средняя.
- Связь с позиционированием НИИ: Демонстрирует патриотичную, но предельно трезвую, прагматичную и технократичную позицию. НИИ позиционируется как уникальная площадка, где российская фундаментальная кибернетическая наука встречается с жесткими стандартами METR и NIST.
- Источники для исследования: Научные публикации ИСП РАН 27, методология бенчмарка MERA 39, стандарты оценки METR.10
- Объём материала: 25 000 знаков.
- Сложность производства: Средняя.
- Риски темы: Высочайший риск скатывания в идеологизированный, «квасной патриотизм» или политизированную публицистику. Автору необходимо строго сохранять холодный, аналитический тон, свойственный отчетам RAND Corporation.
Тема 6: AI-Агенты и Право: Проблема распределения ответственности при автоматизированном принятии решений (Automated Decision-Making)
- Почему это перспективно к 2027-2030: Появление множественных, неизбежных судебных прецедентов (например, когда корпоративный ИИ-агент подпишет коммерчески убыточный контракт без участия человека или неправомерно заблокирует финансовую транзакцию) потребует срочного создания новых правовых режимов распределения ответственности (liability frameworks).
- Целевая аудитория: Инхаус-юристы, партнеры юридических фирм, регуляторы.
- Основные тезисы:
Юридическая и технологическая пропасть между чат-ботом и агентом: разница между безответственной генерацией текста на экране и совершением юридически значимого действия через вызов API.
Обзор формирующихся мировых прецедентов: кто в конечном итоге платит за ошибку агента — провайдер базовой модели (Anthropic), IT-интегратор или конечный пользователь?
Строгий технический аудит и внедрение слоев формальной верификации (LTL-оркестрация) как единственный рабочий способ для IT-интегратора защитить свою компанию от разрушительной субсидиарной ответственности.
- SEO-потенциал: ответственность ии агентов, ии автоматизированное принятие решений суд, ai liability framework legal, ошибка ии кто виноват. Конкуренция: низкая.
- Связь с позиционированием НИИ: Органично демонстрирует уникальный сплав 20-летнего адвокатского опыта руководителя НИИ (А.А. Фищука) в сфере банкротств и корпоративного права с передовой кибернетической и технологической базой института.
- Источники для исследования: Законодательство США об ответственности ИИ (California SB 53, анализ судебных прецедентов) 4, нормативные акты UK HSE.6
- Объём материала: 15 000 – 20 000 знаков.
- Сложность производства: Средняя (требует преимущественно правового и системного анализа).
- Риски темы: Материал может быть воспринят читателем как чисто юридическая, теоретическая статья. Жизненно необходимо плотно привязать правовую аргументацию к технологической необходимости внедрения систем FSM-оркестрации.
Тема 7: Ошибка выжившего в SaMD (Software as a Medical Device): Почему вероятностным LLM категорически нельзя доверять диагностику
- Почему это перспективно к 2027-2030: Неконтролируемый бум внедрения генеративного ИИ в телемедицинские сервисы неизбежно приведет к волне скрытых врачебных ошибок (silent failures). Это спровоцирует жесткую реакцию регуляторов и потребует радикального пересмотра стандартов сертификации медицинского алгоритмического ПО.
- Целевая аудитория: Chief Medical Officers (руководители медицинских холдингов), регуляторы здравоохранения (Росздравнадзор), производители MedTech.
- Основные тезисы:
Специфика архитектуры: галлюцинации LLM в медицинской сфере невозможно полностью устранить ни путем RLHF дообучения, ни экстенсивным увеличением параметров модели.
Математические инструменты моделирования уровня неопределенности (uncertainty quantification): как ИИ должен алгоритмически «понимать» и сигнализировать, что он не знает точного ответа.
Необходимость гибридной медицинской архитектуры: нейросеть должна работать исключительно как NLP-интерфейс (переводчик) к строго верифицированной детерминированной медицинской онтологии (на базе исследований МФТИ и подходов AgentVerify).
- SEO-потенциал: вероятностный ии в медицине, ai samd certification, ошибки llm диагноз риски, uncertainty modeling medical ai. Конкуренция: низкая.
- Связь с позиционированием НИИ: Открывает для института высокомаржинальную нишу аудита и сертификации ИИ-решений для частной медицины и производителей медицинского оборудования.
- Источники для исследования: Научные препринты МФТИ по uncertainty in medical AI 32, архитектура AgentVerify в применении к healthcare 13, стандарты FDA/EU MDR.
- Объём материала: 15 000 знаков.
- Сложность производства: Средняя.
- Риски темы: Требуется абсолютная точность в использовании медицинской и нормативной терминологии. Существует риск вступления в конфронтацию с корпоративным хайпом на B2C «ИИ-врачах» от IT-гигантов; критика должна быть выверена, академична и обоснована.
Тема 8: Безопасность ИИ в критической инфраструктуре: Уроки британского регулятора (HSE) для российской промышленности
- Почему это перспективно к 2027-2030: Массовая интеграция компьютерного зрения и агентов предиктивной аналитики на производственных линиях и транспорте потребует создания принципиально новых, жестких регламентов охраны труда, где ИИ будет рассматриваться как самостоятельный фактор промышленного риска.
- Целевая аудитория: Директора по производству, инженеры промышленной безопасности (HSE), корпорации (Промышленность, Нефтегаз, Транспорт), профильные регуляторы (Ростехнадзор).
- Основные тезисы:
Фундаментальные системные угрозы: деградация компетенций живого оператора (deskilling) и избыточное, некритичное доверие к показаниям ИИ (overdependence) как главные катализаторы промышленных катастроф будущего.
Анализ подхода британского регулятора Health and Safety Executive: классификация ИИ-риска как разновидности классического производственного риска. Обязательность процедур вероятностной оценки (probabilistic model checking) перед внедрением на объект.
Техническая реализация концепта Human-Oversight: как через архитектуру оркестратора формально и программно гарантировать, что живой оператор сохраняет безусловный приоритет контроля над системой в любой нештатной ситуации (ограничение Levels of Automation).
- SEO-потенциал: ии безопасность на производстве, human oversight ai industry, промышленный ИИ риски охрана труда, ai automation risks manufacturing. Конкуренция: низкая.
- Связь с позиционированием НИИ: Позволяет НИИ выйти на чрезвычайно платежеспособный рынок промышленных корпораций через призму абсолютно понятных для них категорий (охрана труда, промышленная безопасность, предотвращение аварий).
- Источники для исследования: Официальные гайдлайны UK HSE 6, профильные академические статьи по проблематике Human-in-the-Loop.7
- Объём материала: 15 000 – 18 000 знаков.
- Сложность производства: Средняя.
- Риски темы: Тема может легко сместиться слишком далеко от ключевого профиля НИИ (глубокие LLM и LLM-агенты) в сторону обсуждения примитивных систем компьютерного зрения (контроль касок на стройке). Автору необходимо жестко удерживать фокус именно на сложных, мультимодальных агентах управления производственными процессами.
БЛОК 5. РЕКОМЕНДАЦИИ ПО ВЫБОРУ ТРЁХ ТЕМ ДЛЯ ЗАПУСКА
Для успешного запуска первой стратегической серии лонгридов на сайте isslab.ru рекомендуется выбрать следующие три темы. Этот выбор обусловлен необходимостью формирования логически замкнутого цикла позиционирования: от постановки болезненной юридической проблемы для бизнеса, через предложение стандарта международного аудита в качестве инструмента управления, к демонстрации высшего технического пилотажа математической верификации.
1. Тема 6: AI-Агенты и Право: Проблема распределения ответственности при автоматизированном принятии решений
- Аудитория: Юристы, регуляторы, топ-менеджмент (C-level).
- Стратегическое обоснование: В маркетинговой воронке НИИ эта статья выполняет критическую функцию «Лидогенератора» (The Hook). Она описывает новейшую технологическую проблему исключительно на языке бизнеса и права, актуализируя у менеджмента страх потери операционного контроля и возникновения непредсказуемой финансовой ответственности за действия ИИ. Наличие обширного адвокатского бэкграунда у руководителя НИИ делает правовую и системную экспертизу в этой статье бескомпромиссно авторитетной. Статья ставит ребром вопрос «Кто будет платить за ошибку?», чтобы следующие публикации могли дать прагматичный ответ «Что нужно делать».
- Сложность: Средняя (статья имеет низкий порог входа для C-level читателя, так как не перегружена кодом и математикой).
2. Тема 3: Стандарт ISO/IEC 42001 и дедлайны EU AI Act: Прагматичный гайд по сертификации ИИ
- Аудитория: B2B-интеграторы, комплаенс-офицеры, корпоративные заказчики.
- Стратегическое обоснование: Эта статья играет роль «Продающей методологии» (The Bridge). Она напрямую связывает катастрофические юридические риски, описанные в первой статье, с конкретными, уже существующими международными стандартами аудита. Текст позиционирует НИИ Системного синтеза как институцию, которая глубоко и органично интегрирована в глобальный бюрократический и инженерный контекст (фреймворки NIST, ISO, EU Act). Это создает мощный фундамент для прямой продажи услуг независимого аудита и консалтинга для крупных корпораций, стремящихся защитить свои инвестиции в ИИ.
- Сложность: Средняя (требует скрупулезного системного анализа нормативных документов, но сохраняет читаемость для менеджеров).
3. Тема 1: От вероятности к доказательству: Формальная верификация ИИ-агентов через оркестрацию конечных автоматов
- Аудитория: Технические директора (CTO), Data Scientists, академическое сообщество.
- Стратегическое обоснование: Третий лонгрид служит «Техническим доказательством экспертизы» (The Authority Proof). Это сложный, глубоко проработанный текст для профильных специалистов. Он должен продемонстрировать рынку, что НИИ не просто читает и переводит западные законы, но и досконально, на уровне математики владеет инженерным аппаратом. Детальный разбор темпоральной логики (LTL), архитектуры конечных автоматов и сред вроде AgentVerify/VeriGuard навсегда отделит НИИ в глазах квалифицированного читателя от корпоративных пиарщиков и поверхностных консультантов.
- Сложность: Высокая (требует фронтирной технической аналитики и понимания computer science).
БЛОК 6. ИСТОЧНИКИ, КОТОРЫЕ НЕ НУЖНО ИСПОЛЬЗОВАТЬ (ИМИДЖЕВЫЙ МУСОР)
Для безусловного соблюдения стандартов чистоты исследования и академической строгости, в процессе сбора информации и подготовки отчета был идентифицирован и намеренно проигнорирован массив источников, классифицированных исключительно как маркетинговые коммуникации. Использование таких источников категорически неприемлемо для подготовки экспертных лонгридов НИИ Системного синтеза. Ниже приведена классификация отсеянного материала.
Категория источника | Пример материала | Причина исключения из исследования |
|---|---|---|
B2C Пресс-релизы IT-гигантов | Анонсы Сбера о новых навыках GigaChat для массового потребителя (уровень «GigaChat научился писать стихи»). | Материалы для массовых СМИ не содержат описания архитектуры, методов обучения и строгих метрик безопасности. (Примечание: При этом глубокие технические публикации разработчиков Сбера на arXiv для открытой модели 3.1-Ultra 35 валидны и использованы в отчете). |
Продуктовый маркетинг корпораций | Публикации Яндекс (Yandex B2B Tech) о том, как YandexGPT 5.1 Pro «автоматизирует рутину».26 | Блоги описывают исключительно коммерческие продуктовые фичи для продаж, не предоставляя датасетов верификации или результатов независимых технических бенчмарков по AI Safety. |
Отчеты об устойчивом развитии (ESG) | MTS Sustainability Report 2024 с упоминанием ИИ-инициатив.49 | ИИ упоминается в корпоративных отчетах исключительно в имиджевом контексте «экологичности» или общих, ни к чему не обязывающих деклараций об этике. Упоминание «запуска ИИ-решений на базе Cotype Pro 2» не раскрывает механизмов защиты данных. |
Журналистские B2C тестирования | Популярные обзоры в СМИ формата «Мы задали 10 каверзных вопросов ChatGPT, YandexGPT и GigaChat».50 | Эмпирические тесты журналистов методологически ничтожны. Они не используют стандартизированные методы оценки (evals), не контролируют утечки данных и не оценивают границы безопасности (alignment) моделей. |
Популярная футурология | Колонки в медиа с заголовками в духе «Появление AI-ученого и замена юристов к 2030 году».51 | Публицистика лишена технической конкретики. В качественной аналитике вместо футурологии должны использоваться только верифицируемые дорожные карты фронтир-лабораторий (например, Anthropic 1) и аналитические прогнозы (METR 10). |
Источники
Frontier Safety Roadmap \ Anthropic, дата последнего обращения: мая 5, 2026, https://anthropic.com/responsible-scaling-policy/roadmap
An Outsider’s Roadmap into AI Safety Research (2025) — LessWrong, дата последнего обращения: мая 5, 2026, https://www.lesswrong.com/posts/bcuzjKmNZHWDuEwBz/an-outsider-s-roadmap-into-ai-safety-research-2025
AgentVerify: Compositional Formal Verification of AI Agent Safety …, дата последнего обращения: мая 5, 2026, https://www.preprints.org/manuscript/202604.1029/v1
2026 AI Legal Forecast: From Innovation to Compliance | Baker Donelson, дата последнего обращения: мая 5, 2026, https://www.bakerdonelson.com/2026-ai-legal-forecast-from-innovation-to-compliance
Global Regulatory Frameworks for the Use of Artificial Intelligence (AI) in the Healthcare Services Sector — PMC, дата последнего обращения: мая 5, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC10930608/
HSE’s regulatory approach to Artificial Intelligence (AI) – News, дата последнего обращения: мая 5, 2026, https://www.hse.gov.uk/news/hse-ai.htm
Risk and Reliability Evaluation of Future Industrial Automation Systems: A Systematic Literature Review and Research Agenda, дата последнего обращения: мая 5, 2026, https://asmedigitalcollection.asme.org/risk/article/12/2/020801/1229822/Risk-and-Reliability-Evaluation-of-Future
Human Expertise for AI Red-Teaming and Scalable Evaluation — ResearchGate, дата последнего обращения: мая 5, 2026, https://www.researchgate.net/publication/403756120_Human_Expertise_for_AI_Red-Teaming_and_Scalable_Evaluation
AgentVerify: Compositional Formal Verification of AI Agent Safety Properties via LTL Model Checking — Preprints.org, дата последнего обращения: мая 5, 2026, https://www.preprints.org/manuscript/202604.1029
Common Elements of Frontier AI Safety Policies (December 2025 …, дата последнего обращения: мая 5, 2026, https://metr.org/blog/2025-12-09-common-elements-of-frontier-ai-safety-policies/
AgentVerify: Compositional Formal Verification of AI Agent Safety Properties via LTL Model Checking — Preprints.org, дата последнего обращения: мая 5, 2026, https://www.preprints.org/frontend/manuscript/54b7f29545add4baf7d8a4271c50b6d0/download_pub
Agent Behavioral Contracts: Formal Specification and Runtime Enforcement for Reliable Autonomous AI Agents — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/html/2602.22302v1
[2510.05156] VeriGuard: Enhancing LLM Agent Safety via Verified Code Generation — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/abs/2510.05156
VeriGuard: Enhancing LLM Agent Safety via Verified Code Generation — Google Research, дата последнего обращения: мая 5, 2026, https://research.google/pubs/veriguard-enhancing-llm-agent-safety-via-verified-code-generation/
VeriGuard: Enhancing LLM Agent Safety via Verified Code Generation — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/html/2510.05156v1
VeriGuard: Enhancing LLM Agent Safety via Verified Code Generation | OpenReview, дата последнего обращения: мая 5, 2026, https://openreview.net/forum?id=SnEywLKodN
дата последнего обращения: января 1, 1970, https://artificialintelligenceact.eu/high-risk-ai-systems/
EU AI Act vs NIST AI RMF vs ISO/IEC 42001: A Plain English Comparison — EC-Council, дата последнего обращения: мая 5, 2026, https://www.eccouncil.org/cybersecurity-exchange/responsible-ai-governance/eu-ai-act-nist-ai-rmf-and-iso-iec-42001-a-plain-english-comparison/
EU Standardization Supporting the Artificial Intelligence Act | Insights — Skadden Arps, дата последнего обращения: мая 5, 2026, https://www.skadden.com/insights/publications/2024/10/eu-standardization-supporting-the-artificial-intelligence-act
Responsibilities of the European Commission (AI Office) | EU Artificial Intelligence Act, дата последнего обращения: мая 5, 2026, https://artificialintelligenceact.eu/responsibilities-of-european-commission-ai-office/
The EU AI Act implementation timeline: understanding the next deadline for compliance, дата последнего обращения: мая 5, 2026, https://www.kennedyslaw.com/en/thought-leadership/article/2026/the-eu-ai-act-implementation-timeline-understanding-the-next-deadline-for-compliance/
Preparing for EU AI Act Compliance with ISO 42001 — A-LIGN, дата последнего обращения: мая 5, 2026, https://www.a-lign.com/articles/preparing-for-eu-ai-act-compliance
Implementation Timeline | EU Artificial Intelligence Act, дата последнего обращения: мая 5, 2026, https://artificialintelligenceact.eu/implementation-timeline/
Global standards for AI governance: EU AI Act, ISO 42001 and NIST compared — Modulos AI, дата последнего обращения: мая 5, 2026, https://www.modulos.ai/blog/global-standards-for-ai-governance/
Large language models reflect the ideology of their creators — PMC, дата последнего обращения: мая 5, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC12779552/
YandexGPT — TAdviser, дата последнего обращения: мая 5, 2026, https://tadviser.com/index.php/Product:YandexGPT
Trusted artificial intelligence — Avetisyana — Herald of the Russian …, дата последнего обращения: мая 5, 2026, https://journals.eco-vector.com/0869-5873/article/view/659665
SANER 2026 — Research Track — conf.researchr.org, дата последнего обращения: мая 5, 2026, https://conf.researchr.org/track/saner-2026/saner-2026-papers
SANER 2026 — Registered Report Track, дата последнего обращения: мая 5, 2026, https://conf.researchr.org/track/saner-2026/saner-2026-registered-report-track-
Emergent Misalignment via In-Context Learning: Narrow in-context examples can produce broadly misaligned LLMs — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/html/2510.11288v4
MTS AI Releases Cotype Pro 2, Second-Generation Business-Focused LLM, дата последнего обращения: мая 5, 2026, https://mts.ai/en/tech/mts-ai-releases-cotype-pro-2-second-generation-business-focused-llm/
Enhancing the Reliability of Medical AI through Expert-guided Uncertainty Modeling — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/html/2604.01898v1
Nikolay SHILOV | Senior Researcher | PhD | Laboratory of Computer-Aided Integrated Systems — ResearchGate, дата последнего обращения: мая 5, 2026, https://www.researchgate.net/profile/Nikolay-Shilov-3
Nikolay Shilov — Google Scholar, дата последнего обращения: мая 5, 2026, https://scholar.google.com/citations?user=kEHqrCcAAAAJ&hl=en
New open weights models: GigaChat-3.1-Ultra-702B and GigaChat-3.1-Lightning-10B-A1.8B : r/LocalLLaMA — Reddit, дата последнего обращения: мая 5, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1s2pkfw/new_open_weights_models_gigachat31ultra702b_and/
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) — ACL Anthology, дата последнего обращения: мая 5, 2026, https://aclanthology.org/volumes/2025.acl-demo/
T-pro 2.0: An Efficient Russian Hybrid-Reasoning Model and Playground — ACL Anthology, дата последнего обращения: мая 5, 2026, https://aclanthology.org/2026.eacl-demo.22.pdf
T-pro 2.0: An Efficient Russian Hybrid-Reasoning Model and Playground — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/html/2512.10430v1
MERA (Multimodal Evaluation for Russian-language Architectures) is a new open benchmark for the Russian language for evaluating SOTA models. — GitHub, дата последнего обращения: мая 5, 2026, https://github.com/MERA-Evaluation/MERA
Multimodal Evaluation of Russian-language Architectures — ACL Anthology, дата последнего обращения: мая 5, 2026, https://aclanthology.org/2026.eacl-long.94.pdf
Multimodal Evaluation of Russian-language Architectures — arXiv, дата последнего обращения: мая 5, 2026, https://arxiv.org/html/2511.15552v3
Guidelines and Regulations to Provide Insights on Public Policies to Ensure Artificial Intelligence’s Beneficial Use as a Professional Tool — International Bar Association, дата последнего обращения: мая 5, 2026, https://www.ibanet.org/medias/anlbs-ai-working-group-report-feb-2026.pdf?context=bWFzdGVyfFB1YmxpY2F0aW9uUmVwb3J0c3wzMTgzODI3fGFwcGxpY2F0aW9uL3BkZnxhREUzTDJnek9TODVNekl4T0RVeE1qZzVOak13TDJGdWJHSnpMV0ZwTFhkdmNtdHBibWN0WjNKdmRYQXRjbVZ3YjNKMExXWmxZaTB5TURJMkxuQmtaZ3w2NWYyYzYyNzNhNjJkZDM2YTBlOTFhMWVmMjExMjdjNjc5YTc0MzZjMTMzYzZiZjI5MzE0NTY2YzAxNTI0MTAy
Journal of Digital Technologies and Law, дата последнего обращения: мая 5, 2026, https://www.lawjournal.digital/jour
Cyber Physical Systems Security: Bridging Privacy, Verification, Intelligence, and Forensics — IEEE Xplore, дата последнего обращения: мая 5, 2026, https://ieeexplore.ieee.org/iel8/6287639/6514899/11413910.pdf
AI in Health & Safety: Complete Guide 2026 | Arinite, дата последнего обращения: мая 5, 2026, https://www.arinite.com/blog/how-artificial-intelligence-is-transforming-health-and-safety-at-work
2026 AI Laws Update: Key Regulations and Practical Guidance — Gunderson Dettmer, дата последнего обращения: мая 5, 2026, https://www.gunder.com/en/news-insights/insights/2026-ai-laws-update-key-regulations-and-practical-guidance
Annual science review — HSE, дата последнего обращения: мая 5, 2026, https://www.hse.gov.uk/research/review.htm
Program for Tuesday, June 17th — EasyChair, дата последнего обращения: мая 5, 2026, https://easychair.org/smart-program/ESRELSRA-E2025/2025-06-17.html
MTS GROUP SUSTAINABILITY REPORT 2024, дата последнего обращения: мая 5, 2026, https://storage.ir.mts.ru/mts-ir/images/documents/MTS-Sustainability-report_2024-eng.pdf
We compare Chat GPT, Gemini, Gigachat and YandexGPT. Strong language models (and not so strong) — C Cases, дата последнего обращения: мая 5, 2026, https://www.ccases.ceo/en/insights/chat-gpt-gemini-gigachat-i-yandexgpt
The Future of AI Regulation: What’s Coming in 2026–2030 (And How to Prepare Now) | by Manish Atri — Medium, дата последнего обращения: мая 5, 2026, https://medium.com/@atri_iiita/the-future-of-ai-regulation-whats-coming-in-2026-2030-and-how-to-prepare-now-0e1b281b6630


