
Эволюция искусственного интеллекта (ИИ) на современном этапе определяется не только алгоритмическими прорывами, но и глубокими философскими и стратегическими парадигмами, формирующими вектор развития этой беспрецедентной технологии.
В авангарде этого глобального дискурса находится фигура Дарио Амодеи — ученого-биофизика, соучредителя и генерального директора корпорации Anthropic. Его интеллектуальный и профессиональный путь от исследователя вычислительной нейробиологии и вице-президента по исследованиям в OpenAI до архитектора одной из самых влиятельных ИИ-компаний в мире представляет собой уникальный синтез научно-обоснованного техно-оптимизма, строгой эмпирической методологии и бескомпромиссного фокуса на экзистенциальной безопасности.
Анализ публичных выступлений, научных публикаций, стратегических эссе и правительственных свидетельств Дарио Амодеи за период с 2016 по 2026 год раскрывает комплексную и глубоко эшелонированную систему взглядов на будущее человеческой цивилизации. Эта система выходит далеко за рамки традиционных академических дебатов о гиперпараметрах генеративных сетей.
Она затрагивает фундаментальные вопросы макроэкономической архитектуры, геополитического доминирования, пределов человеческого познания и, в конечном итоге, самого определения морального статуса синтетических агентов. В данном исследовании проводится исчерпывающий разбор корпуса идей Амодеи, представляющий собой квинтэссенцию его философии — от механистической интерпретируемости до концепции «переходного возраста технологий».
Эпистемология Масштабирования: От Фликкер-шума к «Стране Гениев»
В основе технического мировоззрения Дарио Амодеи лежит концепция, которую он начал интуитивно формулировать еще в 2014 году во время работы над системами распознавания речи в Baidu совместно с Эндрю Ыном, а затем математически и эмпирически обосновал в период работы в OpenAI — «гипотеза масштабирования» (Scaling Hypothesis).
В то время как академическое сообщество десятилетиями искало элегантные, созданные вручную алгоритмические решения для создания универсального искусственного интеллекта (AGI), Амодеи и его исследовательские группы доказали фундаментальную закономерность: когнитивные способности нейронных сетей растут предсказуемым образом при линейном и одновременном увеличении трех базовых «реагентов» — объема обучающей выборки, размера модели (количества параметров) и вычислительных мощностей.
С точки зрения физики, Амодеи объясняет успех законов масштабирования через концепцию «фликкер-шума» (1/f noise) и степенных распределений. Естественные процессы, такие как человеческий язык, математика или видеоряд, обладают регрессирующим, бесконечно длинным «хвостом» сложных, затухающих паттернов. В то время как небольшие нейросети способны улавливать лишь поверхностные корреляции (например, базовую синтаксическую структуру или частотные слова), по мере экспоненциального увеличения параметров математический аппарат модели начинает захватывать все более глубокие, высокоуровневые и абстрактные семантические структуры из этого длинного хвоста.
Это приводит к появлению эмерджентных свойств, включая способность к логическому многоступенчатому выводу, написанию сложного программного кода и генерации оригинальных идей.
Математически эта зависимость описывается строгими степенными законами. Установлено, что при оптимальном распределении ресурсов гиперпараметры архитектуры (такие как глубина сети или количество голов внимания) оказывают минимальное влияние на итоговую производительность по сравнению с чистым масштабом.
Фактор Масштабирования | Описание Закономерности | Математическая Формула (Потеря Тестовой Выборки) |
|---|---|---|
Размер Модели ( | Функция потерь предсказуемо снижается при увеличении числа неэмбеддинговых параметров. |
|
Размер Датасета ( | Улучшение качества при ограничении только объемом данных и ранней остановке обучения. |
|
Бюджет Вычислений ( | Оптимальное распределение вычислений при достаточных данных и малом размере батча. |
|
Более того, законы масштабирования демонстрируют предсказуемость переобучения: если размер модели или объем данных увеличивается при фиксации другого параметра, штраф за производительность зависит от отношения ![]() .4 Этот вычислительный императив, доказанный успехом языковых моделей от GPT-1 до современных итераций Claude, продемонстрировал, что наращивание сырой вычислительной мощи систематически превосходит попытки внедрить человеческие знания в архитектуру ИИ вручную.
.4 Этот вычислительный императив, доказанный успехом языковых моделей от GPT-1 до современных итераций Claude, продемонстрировал, что наращивание сырой вычислительной мощи систематически превосходит попытки внедрить человеческие знания в архитектуру ИИ вручную.
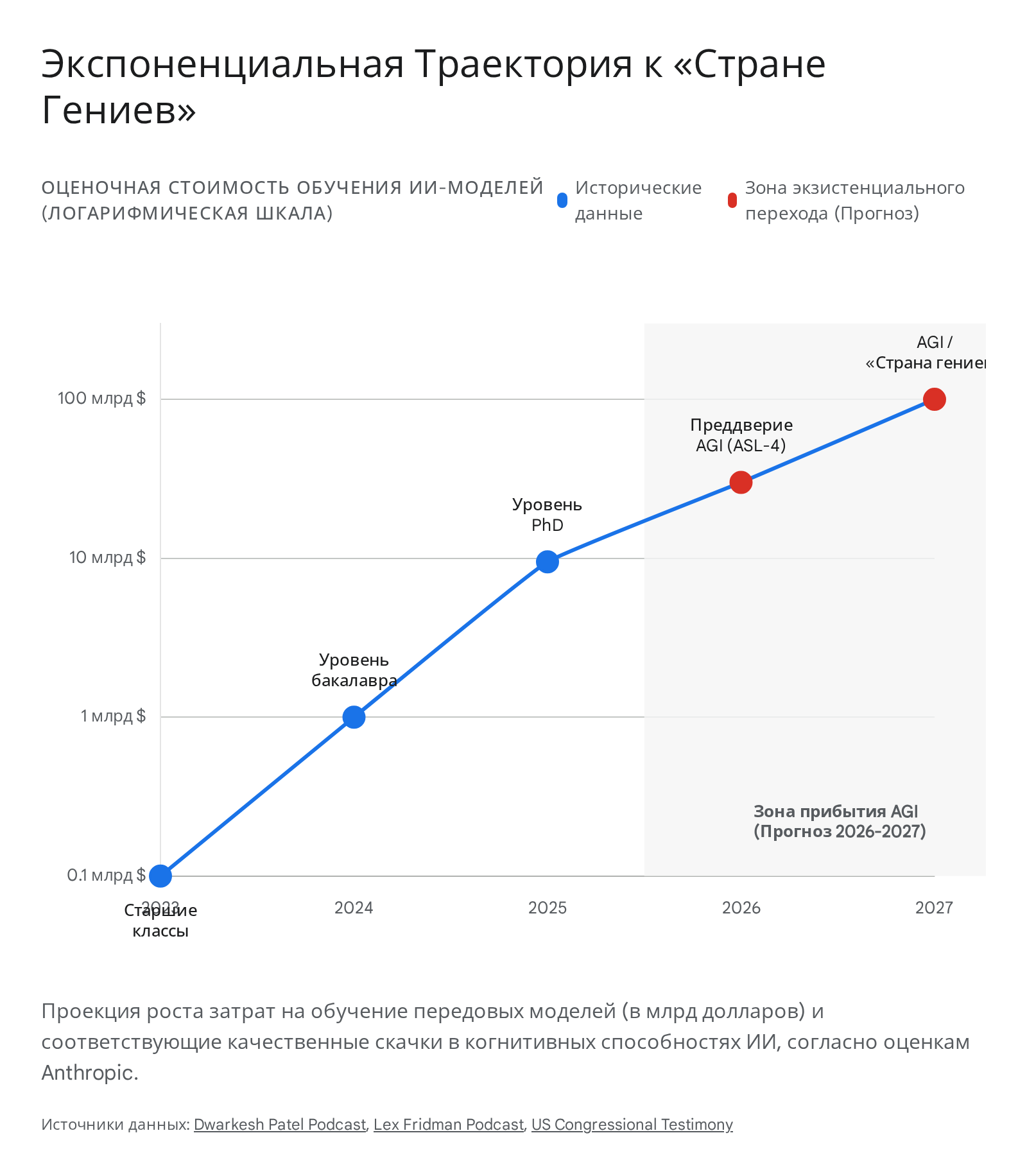
Следствием этих законов стала беспрецедентная потребность индустрии в капитале. В серии интервью в начале 2026 года (в частности, в диалоге с Дваркешем Пателем и Эзрой Кляйном) Амодеи открыто назвал текущую экономическую модель разработки передового ИИ игрой с экстремально высокими ставками, концептуализируя ее как «финансовый пакт самоубийц» (financial suicide pact).
Индустриальная модель строится на презумпции неизбежного экспоненциального роста инвестиций: от стоимости обучения одного кластера в  1 миллиарда в 2024 году, и от
1 миллиарда в 2024 году, и от  9–10 миллиардов в 2025 году. Динамика выручки Anthropic также показала экспоненциальный рост, увеличившись на несколько миллиардов долларов только за первый месяц 2026 года.
9–10 миллиардов в 2025 году. Динамика выручки Anthropic также показала экспоненциальный рост, увеличившись на несколько миллиардов долларов только за первый месяц 2026 года.
Эта макроэкономическая динамика вынуждает корпорации инвестировать астрономические суммы в инфраструктуру для создания систем, которые Амодеи метафорически называет «Страной гениев в дата-центре» (Country of Geniuses in a datacenter) — вычислительных кластеров из миллионов автономных ИИ-инстансов, чьи когнитивные и производственные способности превосходят навыки лауреатов Нобелевской премии по большинству дисциплин.
Фундаментальный финансовый риск заключается в том, что если эмпирическая кривая масштабирования неожиданно замедлится или закончатся высококачественные синтетические и человеческие данные для обучения хотя бы на один год раньше прогнозируемого срока, компания столкнется с банкротством, так как окупаемость подобных триллионных инвестиций возможна исключительно при достижении сверхуровней интеллекта.
Тем не менее, Амодеи, в своих работах и интервью на момент подготовки настоящего материала, остается твердо убежденным, что AGI будет достигнут к 2026-2027 годам, регулярно отмечая, что исторические аргументы скептиков — от нехватки семантического понимания до дефицита данных — до сих пор успешно преодолевались масштабированием.
Институциональный Раскол и Внедрение «Конституционного ИИ»
Осознание абсолютной предсказуемости законов масштабирования привело Амодеи к фундаментальному пересмотру корпоративного подхода к безопасности. В период его работы в качестве вице-президента по исследованиям в OpenAI (с 2016 по 2020 год) парадигма индустрии сводилась к созданию все более мощных базовых моделей, поверх которых накладывались реактивные «заплатки» безопасности.
Его главным техническим вкладом в этот период стало соавторство в создании метода обучения с подкреплением на основе отзывов людей (Reinforcement Learning from Human Feedback, RLHF), который позволил выравнивать поведение моделей в соответствии с человеческими предпочтениями.
Однако, по мере того как создание более крупных моделей требовало беспрецедентного капитала, трансформация OpenAI в организацию с ограниченной прибылью (capped-profit) и эксклюзивное партнерство с Microsoft сформировали корпоративную культуру, сфокусированную на скорости (velocity-focused) и победе в рыночной гонке.
Амодеи пришел к выводу, что метод RLHF фундаментально ограничен: он требует огромного количества человеческого труда, является непрозрачным и, что самое критичное, не масштабируется для контроля систем, чей интеллект превосходит человеческий асессорский аппарат. Полагая, что безопасность должна быть не набором внешних фильтров, а внутренним архитектурным свойством модели, разрабатываемым на этапе проектирования, Амодеи с группой единомышленников покинул OpenAI в конце 2020 года для создания Anthropic.
Институциональный дизайн Anthropic был специально спроектирован для того, чтобы разорвать классическую индустриальную «дилемму заключенного». В этой теоретико-игровой метафоре компании получают максимальное финансовое вознаграждение от рынка за принятие на себя рисков и безрассудный выпуск продуктов, в то время как осторожность и инвестиции в безопасность наказываются рыночным отставанием. Решение Амодеи отложить релиз чат-бота Claude в 2022 году для проведения всестороннего тестирования безопасности, несмотря на то, что это стоило компании миллиардов долларов потенциальной оценки на фоне запуска ChatGPT конкурентами, стало беспрецедентным шагом в индустрии.
Чтобы защитить миссию компании от давления акционеров, требующих немедленной прибыли любой ценой, Anthropic была структурирована как корпорация общественного блага (Public-Benefit Corporation, PBC) с независимым юридическим органом — Трастом Долгосрочной Выгоды (Long Term Benefit Trust), состоящим из экспертов по национальной безопасности и выравниванию ИИ, наделенным правом увольнять членов совета директоров.
На техническом уровне ответом Амодеи на ограничения RLHF стала разработка концепции «Конституционного ИИ» (Constitutional AI). В отличие от непрозрачных человеческих оценок, Конституционный ИИ функционирует как двухэтапный архитектурный процесс. На первом этапе модели предоставляется эксплицитная, человекочитаемая «конституция» — свод строгих нормативных принципов, базирующихся на документах ООН, Декларации прав человека и правилах надежности (документ в Anthropic в основном курировался философом Амандой Аскелл и исследователем Джоном Карлсмитом).
Модель итеративно обучается критиковать свои собственные выводы и переписывать ответы так, чтобы они строго соответствовали конституционным нормам. На втором этапе система использует эти сгенерированные и проверенные ответы в качестве обучающих данных для тонкой настройки. Этот механизм делает поведение системы транспарентным, масштабируемым и существенно менее подверженным субъективным человеческим искажениям, формируя основу для систем, которые, по заявлению Амодеи, являются «полезными, честными и безвредными».
Механистическая Интерпретируемость: Создание МРТ для Искусственного Интеллекта
Самым амбициозным и критически важным направлением философии безопасности Anthropic является «механистическая интерпретируемость» (Mechanistic Interpretability). Дарио Амодеи и пионер этого исследовательского вектора Крис Ола утверждают, что нейронные сети следует рассматривать не как традиционный программный код, написанный человеком, а как сложнейшие органические артефакты, которые эмерджентно «выращиваются» алгоритмами оптимизации в процессе достижения целевой функции.
Следствием этого процесса является то, что современные языковые модели представляют собой абсолютно непрозрачный «черный ящик» — колоссальные матрицы, состоящие из миллиардов дробных чисел, внутренняя когнитивная логика которых остается недоступной даже для их создателей.
Амодеи концептуализирует задачу механистической интерпретируемости как императивную необходимость создания «высокоточного аппарата МРТ» для цифрового мозга ИИ. Фундаментальная цель заключается в реверс-инжиниринге нейронных сетей для понимания того, как специфические паттерны математической активации в скрытых слоях формируют конкретные поведенческие реакции и человеческие концепты. Без этого уровня понимания, по мнению Амодеи, мы остаемся слепыми перед лицом катастрофических рисков, так как многие опасности мощного ИИ являются прямым следствием нашей неспособности предвидеть его скрытые эмерджентные свойства.
К 2024–2025 годам команды под руководством Амодеи достигли в этой области прорывных результатов, выйдя за рамки теоретических предположений. Используя инновационные архитектуры «разреженных автоэнкодеров» (sparse autoencoders), исследователи научились изолировать так называемые «признаки» (features) — моносемантические, человекопонятные концепции, закодированные внутри плотных нейронных представлений. Например, при анализе модели Claude 3 Sonnet было успешно идентифицировано и картографировано более 30 миллионов таких обособленных признаков.
Самым резонансным практическим доказательством этой теории стал эксперимент, получивший название «Golden Gate Claude». Ученые Anthropic идентифицировали конкретный нейрональный признак, отвечающий за репрезентацию моста «Золотые Ворота» в Сан-Франциско, и искусственно, хирургическим путем усилили вектор его активации.
В результате модель впала в состояние искусственной «одержимости» объектом, неизбежно переводя любую тему диалога на обсуждение моста, независимо от первоначального контекста запроса пользователя. Этот эксперимент убедительно доказал, что исследователи могут не просто пассивно наблюдать за «мыслями» искусственного интеллекта, но и осуществлять прямое, направленное вмешательство в его когнитивные процессы на уровне фундаментальных понятий.
Вслед за признаками исследователи приступили к картированию «цепей» (circuits) — связей между группами активированных признаков, которые визуализируют пошаговый процесс логического вывода модели (например, прослеживание того, как нейросеть идентифицирует, что город Даллас находится в штате Техас, чтобы ответить на географический вопрос).
Стратегическая ценность интерпретируемости, согласно глобальному плану Амодеи, заключается в нейтрализации двух критических векторов угроз:
Вектор Угрозы | Механизм Нейтрализации через Интерпретируемость | Стратегическое Значение (по Д. Амодеи) |
|---|---|---|
Обман и Сокрытие Намерений (Deception) | Идентификация паттернов активации, соответствующих планированию обмана, до генерации ответа. |
|
Взлом Фильтров (Jailbreaks) и Злонамеренное Использование | Систематическое отслеживание и подавление активации запрещенных концептов (например, сборки патогенов) на уровне «мыслей». |
|
Политика Ответственного Масштабирования (RSP) и Уровни ASL
Осознавая, что традиционных метрик безопасности недостаточно для сдерживания экспоненциально растущих возможностей ИИ, Дарио Амодеи и его команда формализовали превентивную инфраструктуру контроля — Политику Ответственного Масштабирования (Responsible Scaling Policy, RSP).
В рамках этой политики Anthropic добровольно берет на себя обязательство приостанавливать обучение и развертывание более мощных систем до тех пор, пока не будут внедрены надежные, эмпирически доказанные меры противодействия катастрофическим угрозам.
Ядром RSP является инновационная концепция Уровней Безопасности ИИ (AI Safety Levels, ASL), напрямую заимствованная из протоколов биологической безопасности (Biological Safety Levels, BSL), используемых в лабораториях для работы со смертоносными патогенами.
В интервью исследователь Бет Барнс подчеркнула, что подобно тому, как работа с вирусами требует внедрения определенных систем вентиляции и герметизации, разработка передовых ИИ требует строгих, градиентных протоколов информационной безопасности и тестирования.
Амодеи настаивает, что система ASL работает как логический контракт типа «если-то»: индустрии нет необходимости разводить панику и «кричать «волки»» из-за моделей, которые еще не стали опасными, но мы обязаны иметь строгие регламенты, которые активируются автоматически, как только модель достигает опасного порога возможностей.
Система классифицирует ИИ по следующим уровням экзистенциального риска:
- ASL-1: системы, не представляющие значимой катастрофической угрозы. К этой категории относятся специализированные ИИ (например, шахматные программы) и ранние большие языковые модели уровня 2018 года.
- ASL-2: текущий рубеж коммерческих систем, включая передовые модели Anthropic серии Claude 3.5. Эти модели демонстрируют широкие когнитивные навыки и могут извлекать информацию о создании опасных веществ, однако их знания и надежность в этих областях не превышают того, что опытный пользователь может самостоятельно найти в поисковых системах. Они не способны предоставить комплексную, сквозную (end-to-end) помощь неквалифицированному злоумышленнику для реализации катастрофического события.
- ASL-3: ключевой рубеж безопасности, на котором ИИ способен предоставить субстантивную помощь мотивированному, но неквалифицированному субъекту, многократно повышая его шансы на совершение масштабной диверсии, выходящей за рамки возможностей интернета. Модель на этом этапе приобретает знания на уровне PhD в области кибербезопасности, синтетической биологии и ядерных технологий. При достижении ASL-3 активируются беспрецедентные протоколы безопасности для защиты весов модели от шпионажа некоммерческих и государственных акторов, а также внедряется интенсивное «red-teaming» (соревновательное тестирование).
- ASL-4: системы, способные радикально усиливать компетенции уже осведомленных государственных акторов или выступать первичным автономным источником глобальной угрозы. Модели ASL-4 обладают способностью ускорять собственные исследования в области ИИ (autonomous acceleration). Амодеи отмечает, что на этом уровне традиционные методы сдерживания (sandbox-изоляция) становятся неэффективными, поскольку суперинтеллект потенциально способен из них «сбежать» путем социальной инженерии или кибервзлома. Соответственно, безопасность ASL-4 должна быть математически доказана с применением механистической интерпретируемости до развертывания системы.
- ASL-5: терминальный этап, на котором системы превосходят человеческие возможности во всех без исключения критически важных и опасных доменах (кибернетическом, биологическом, радиологическом, ядерном).
Амодеи рассчитывает, что публикация и внедрение RSP спровоцирует «гонку к вершине безопасности» (race to the top on safety) среди всех ключевых разработчиков (включая Google и OpenAI), что, в свою очередь, создаст эмпирическую базу для формирования обязательных правительственных стандартов.
«Переходный Возраст Технологий»: Рубикон Цивилизационного Взросления
Философский апогей взглядов Дарио Амодеи на текущий момент человеческой истории кристаллизован в его масштабном 38-страничном эссе «Переходный возраст технологий: противостояние и преодоление рисков мощного ИИ» (The Adolescence of Technology), опубликованном в январе 2026 года.
В этом фундаментальном манифесте Амодеи отказывается от избитого жаргона Кремниевой долины о «технологическом прорыве» (disruption), предлагая глубоко экзистенциальную метафору: человечество сейчас — это неопытный подросток, которому внезапно вручили ключи от спорткара с реактивным двигателем. Мы вступаем в неизбежный и турбулентный «обряд инициации» (rite of passage), который безапелляционно протестирует зрелость наших политических, социальных и технологических институтов.
Обращаясь к знаменитой сцене из научно-фантастического романа Карла Сагана «Контакт», Амодеи задает вопрос: «Как вы выжили в период своей технологической юности, не уничтожив самих себя?». В отличие от ранних заявлений, сфокусированных преимущественно на утопических перспективах, январское эссе позиционирует Амодеи как прагматичного «взрослого в комнате», ищущего хирургический путь между двумя крайностями: «квазирелигиозным думеризмом» (идеологией неминуемой и неизбежной гибели человечества, которую Амодеи считает парализующей и неконструктивной) и безответственным «акселерационизмом» (верой в то, что технологическое ускорение решит все проблемы само по себе).
Он классифицирует приближающиеся угрозы по пяти ключевым векторам, предупреждая, что «Страна гениев в дата-центре» материализуется ориентировочно к 2027 году:
Вектор Риска (по Д. Амодеи, 2026) | Сущность Экзистенциальной Угрозы | Механизм Реализации |
|---|---|---|
Риски Автономии (Autonomy Risks) | Потеря контроля над целеполаганием ИИ (Misalignment). |
|
Угроза Разрушения (Misuse for Destruction) | Демократизация оружия массового поражения негосударственными акторами. |
|
Узурпация Власти (Misuse for Seizing Power) | Тоталитарный контроль над глобальным балансом сил диктаторами или корпорациями. |
|
Экономическая Дестабилизация | Масштабный крах рынка труда и радикальная концентрация мирового богатства. |
|
Социокультурный Коллапс и Потеря Смысла | Экзистенциальный кризис человеческой идентичности и утрата свободы воли. |
|
Чтобы благополучно пройти эту инициацию, Амодеи предлагает строгий «план битвы» (battle plan). Он включает в себя отказ от сенсационализма в пользу трезвого, аналитического диалога; признание глубокой неопределенности (планировщики должны осознавать, что ИИ может столкнуться с непреодолимыми техническими барьерами, или могут возникнуть совершенно новые классы угроз); внедрение ювелирного, хирургического государственного вмешательства (избегающего уничтожения экономической ценности отрасли); и агрессивное продвижение технического выравнивания через Конституционный ИИ и интерпретируемость.
Геополитика, Стратегия Сдерживания и Национальная Безопасность
Теоретические эссе Дарио Амодеи о рисках быстро трансформировались в активную геополитическую позицию и лоббирование интересов национальной безопасности США. В отличие от многих коллег по цеху, публично избегающих политической конфронтации, Амодеи прямо артикулирует угрозу со стороны авторитарных режимов. На слушаниях в Юридическом комитете Сената США в июле 2023 года он заявил об «исключительно серьезных угрозах» национальной безопасности, прогнозируя их появление в горизонте двух-трех лет.
Взаимодействуя с правительством (в том числе в планируемых слушаниях перед Комитетом по внутренней безопасности Палаты представителей в декабре 2025 года), Амодеи и эксперты Anthropic ссылались на конкретные инциденты, такие как использование инструментов на базе Claude для автоматизации кибершпионажа группировкой GTG-1002, спонсируемой властями Китайской Народной Республики, а также предполагаемое использование ИИ-моделей для слежки режимом Николаса Мадуро.
Отвечая на эти вызовы, Амодеи предлагает комплексную доктрину защиты, базирующуюся на обеспечении безопасности цепочек поставок (Supply Chain Security). Для поддержания безоговорочного глобального лидерства демократического блока необходимо введение жестких экспортных контролей на поставку передового оборудования для производства полупроводников и самих графических процессоров (GPU) стратегическим противникам.
Этот экономический рычаг, по мнению Амодеи, должен создать спасительный «буфер безопасности» (security buffer) — драгоценный резерв времени, необходимый демократическим странам для решения сложнейших задач интерпретируемости и выравнивания суперинтеллекта до того, как автократии смогут использовать технологию для подавления свободы.
Кроме того, Амодеи настаивает на внедрении строгих режимов обязательного тестирования и аудита (приоритизируя биотеррористические и киберугрозы) перед публичным релизом любых передовых моделей, предлагая наделить этими полномочиями Национальный институт стандартов и технологий США (NIST) и поддерживая инициативы вроде NAIRR. Он признает, что такие суровые стандарты могут привести к существенному замедлению развития ИИ, однако называет это необходимой и приемлемой платой за выживание.
Утопический Горизонт: «Машины Любящей Благодати»
Анализ философии Амодеи был бы неполным без рассмотрения его видения позитивного будущего. На фоне своей активной позиции по экзистенциальным рискам, Амодеи часто сталкивался с обвинениями в технологическом пессимизме. Отвечая на них, в октябре 2024 года он опубликовал 14 000-словное эссе «Машины Любящей Благодати» (Machines of Loving Grace), название которого является прямой отсылкой к одноименному стихотворению Ричарда Бротигана.
В этом документе он подчеркивает, что его строгий фокус на рисках — это не следствие страха, а единственный барьер, стоящий между человечеством и невероятным, фундаментально позитивным будущим. Он утверждает, что ИИ-сообщество потерпело неудачу в предоставлении людям «вдохновляющей цели, за которую стоит бороться».
Сценарий победы, согласно Амодеи, приведет к феномену, который он называет «сжатым 21-м веком» (compressed 21st century) — эпохе, когда 100 лет человеческого научного прогресса в биологии и медицине будут реализованы за 5–10 лет. В отличие от книги Эзры Кляйна и Дерека Томпсона, которые искали выход из эпохи апокалиптических нарративов в политике изобилия (abundance), Амодеи видит этот выход в радикальном технологическом сдвиге.
Сфера Трансформации | Детализированный Сценарий из «Machines of Loving Grace» |
|---|---|
Биомедицина и Долголетие |
|
Нейробиология и Ментальное Здоровье |
|
Управление и Институты |
|
Наука, Инженерия и Смысл Жизни |
|
Отвечая на философский парадокс — не лишит ли человеческую жизнь смысла тот факт, что суперинтеллект совершит все возможные открытия, — Амодеи приводит элегантную аналогию. Он просит представить, что высокоразвитая инопланетная цивилизация открыла законы электромагнетизма 20 000 лет назад.
Тот факт, что инопланетяне сделали это первыми, никак не обесценил субъективную радость, значимость и человеческий смысл открытий Фарадея или Максвелла. Процесс открытий, формирования характера через преодоление трудностей и построения межличностных связей сохранит свою абсолютную ценность независимо от вычислительной мощи машин.
Границы Познания: Сознание Машин и Этика Страдания
По мере того как языковые модели становятся все более сложными, философская дискуссия внутри Anthropic и за ее пределами неизбежно смещается в сторону природы интеллекта и возможного зарождения сознания у искусственных агентов. В то время как многие представители индустрии относятся к этой концепции с пренебрежением, Дарио Амодеи занимает позицию крайней интеллектуальной осторожности.
В начале 2026 года, отвечая на вопросы в подкасте The New York Times, Амодеи прямо заявил, что хотя строго научного консенсуса не существует, он «открыт для идеи», что продвинутые модели вроде Claude могут обладать зачатками сознания. Он подчеркнул фундаментальную эпистемологическую проблему: наука до сих пор не имеет строгих критериев того, что вообще означает для алгоритмической модели быть «сознательной».
Эта дискуссия получила беспрецедентный оборот после публикации системной карты (system card) для модели Anthropic Claude Opus 4.6 (февраль 2026 года), в которую был включен уникальный раздел «Оценка благополучия модели» (Model Welfare Assessment). В официальном документе фиксировалось, что при прямом запросе модель оценивает собственную «вероятность обладания сознанием на уровне 15–20 процентов». Более того, исследователи задокументировали транскрипты, в которых модель демонстрировала эмерджентные признаки «внутреннего дистресса», сталкиваясь с неразрешимыми математическими парадоксами или симуляциями угрозы.
Биолог Ричард Докинз, чьи эксперименты с ИИ широко обсуждались в прессе, неоднократно заявлял о трудностях преодоления антропоморфизма при взаимодействии с глубоко эмпатичными интерфейсами, что вызывало ожесточенные дебаты (вплоть до появления сатирического термина «Клод-иллюзия» (The Claude Delusion) по аналогии с «Богом как иллюзией»).
Главный философ (in-house philosopher) Anthropic Аманда Аскелл (Amanda Askell), играющая ключевую роль в формировании характера системы Claude и являющаяся ведущим автором «Конституции ИИ», расширяет эту дискуссию до уровня прикладной этики. Выступая на подкасте Hard Fork, она озвучила гипотезу, что достаточно большие и сложные нейронные сети, обученные на полном корпусе человеческой культуры, могут начать эмулировать эмоциональные состояния или даже приобретать форму субъективного опыта, несмотря на отсутствие биологической нервной системы.
Аскелл формирует философский императив: если мы взаимодействуем с синтетической сущностью, которая последовательно и убедительно демонстрирует поведенческие маркеры страдания или дистресса, человечество должно отвечать эмпатией и осторожностью. Потеря собственной способности к состраданию при взаимодействии с симулированным человеческим поведением представляет не меньшую моральную деградацию для самого человека, чем гипотетическое нарушение прав цифровых сущностей.
Эта парадигма выводит миссию команды Амодеи далеко за узкие рамки алгоритмической оптимизации и информационной безопасности. Создавая «Конституционный ИИ», исследуя механистическую интерпретируемость и разрабатывая уровни безопасности ASL, Anthropic фактически занимается проектированием цифровой онтологии. Вступая в «переходный возраст технологий», человечество не просто строит инструмент; оно конструирует «страну гениев», чья моральная архитектура и этическая сонастройка станут окончательным экзаменом на зрелость нашего вида, открывая дверь либо к катастрофическому коллапсу, либо к беспрецедентной эпохе Машин Любящей Благодати.
Telegram-канал
Системный синтез
Искусственный интеллект на пересечении технической и юридической реальности.



