В индустрии корпоративного программного обеспечения экосистема Palantir Technologies, включающая интегрированные платформы Foundry, Gotham, Apollo и AIP, часто скрыта за плотной завесой геополитического нарратива, маркетинговой риторики и дискуссий об этичности использования технологий двойного назначения.
Компания была основана в 2004 году на базе простой, но революционной для того времени идеи: человеческий мозг является наиболее эффективным инструментом для выявления паттернов в информации, тогда как компьютеры лучше всего справляются с управлением колоссальными объемами данных. Выявление «золотой середины», где аналитики способны полностью реализовать свой интеллектуальный потенциал, опираясь на вычислительную мощь, стало концептуальным фундаментом для создания первой платформы Palantir. С тех пор архитектурная парадигма эволюционировала, и сегодня анализ публичной документации, независимых технических аудитов и инженерных блогов показывает, что Palantir представляет собой не просто набор изолированных аналитических инструментов, дашбордов или озер данных (data lakes), а полноценную «операционную систему для предприятия».
В основе этой архитектурной парадигмы лежит концепция бесшовной интеграции разрозненных информационных активов, сложной бизнес-логики, кинетических действий и гранулярной безопасности в единую графовую структуру, которая позволяет оркестрировать критически важные процессы на стыке человеческого и машинного интеллекта. Академические исследователи и независимые инженеры отмечают, что Palantir намеренно игнорирует традиционный подход к разработке хранилищ данных (Data Warehousing), который доминировал в отрасли на протяжении последних двадцати лет. В то время как остальная часть экосистемы больших данных (Big Data) участвовала в гонке за скоростью загрузки информации и гибкостью парадигмы schema-on-read (схема при чтении), Palantir инвестировала колоссальные ресурсы в решение принципиально иной задачи: определение реальных сущностей в предметной области и семантики их взаимосвязей. В результате была создана жестко интегрированная, проприетарная онтологическая модель, которая поддерживается системой непрерывного развертывания на базе ограничений и уникальной моделью институционального внедрения через передовых инженеров (Forward-Deployed Engineering).
Данный отчет представляет собой исчерпывающий технический разбор методологий, архитектурных паттернов и продуктов Palantir, отделяя реальные инженерные инновации от рыночного шума, а также анализируя фундаментальные риски монополизации технологического стека, с которыми сталкиваются государственные и коммерческие заказчики.
Онтологическая система (Ontology System): Операционное ядро и цифровой двойник
Ядром платформ Foundry и Gotham, а также фундаментом для всех интеграций искусственного интеллекта, является Онтологическая система (Ontology System).
В отличие от классических реляционных баз данных, где основной акцент делается на нормализацию таблиц и управление абстрактными метаданными, или традиционных хранилищ, ориентированных исключительно на аналитику постфактум, онтология Palantir спроектирована как единый операционный уровень. Она абстрагирует нижележащие транзакционные системы, такие как ERP-системы, базы данных CRM, журналы датчиков IoT и хранилища неструктурированных документов, превращая их разрозненные строки и столбцы в полноценного, семантически связанного цифрового двойника организации.
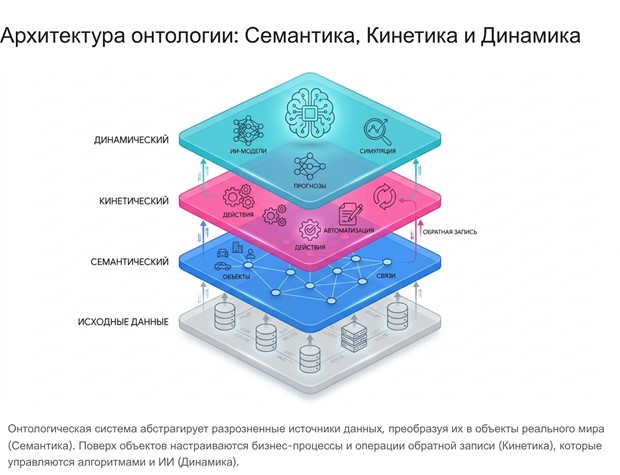
Многоуровневая архитектура онтологии
Техническая архитектура онтологии концептуально и функционально разделена на три взаимосвязанных слоя, каждый из которых выполняет строгую роль в процессе преобразования сырых данных в операционные решения.
- Семантический слой (Semantic Layer): Определяет концептуальную модель предметной области. На этом уровне задаются типы объектов (Object Types), их свойства (Properties) и типы связей (Link Types). Разрозненные записи из десятков различных таблиц связываются в единые, понятные человеку сущности.
- Кинетический слой (Kinetic Layer): Привязывает семантический смысл к реальным действиям и превращает онтологию из статической витрины данных в механизм управления. Он определяет действия (Action Types) и автоматизации, описывая набор мутаций, бизнес-правила валидации и триггеры.
- Динамический слой (Dynamic Layer): Отвечает за глубокую интеграцию моделей машинного обучения (ML) и систем искусственного интеллекта (AI). Позволяет создавать модели, настраивать их прямое развертывание и публиковать функции-обертки для живого логического вывода в пользовательских приложениях.
Архитектурное противопоставление традиционному Semantic Web (RDF/OWL)
В профессиональной среде часто возникает путаница между онтологией Palantir и стандартами Semantic Web (RDF, OWL). Традиционные онтологии фокусируются на статическом представлении фактов и сериализации данных. В отличие от академического подхода, онтология Palantir — это живая операционная система.
Характеристика системы | Традиционный Semantic Web (RDF / OWL) | Palantir Ontology System |
|---|---|---|
Основная архитектурная цель | Статическое представление знаний, связывание открытых данных, семантический машинный логический вывод (inference). | Интеграция данных в цифровых двойников, оркестрация бизнес-процессов, операционное применение искусственного интеллекта. |
Фундаментальная модель данных | Атомарные триплеты (Subject-Predicate-Object) с использованием URI в качестве глобальных идентификаторов. | Высокоуровневые бизнес-сущности: Объекты, Свойства, Связи, Действия (Action Types), глубокая ориентация на процессы. |
Механизмы записи и мутации | Обновление осуществляется через запросы SPARQL Update, что часто ограничено из-за вычислительной сложности поддержки логического вывода. | Нативная, встроенная поддержка механизма Writeback (обратной записи) через транзакционные Действия (Actions). |
Исполнение бизнес-логики | Внешние движки логического вывода (Reasoners), работающие поверх статических правил. | Непосредственная интеграция с масштабируемыми конвейерами Apache Spark, функциями больших языковых моделей и симуляторами. |
Механизм Writeback и переход к парадигме Event Sourcing
Ключевой технологической особенностью, отличающей онтологию Palantir от стандартных систем бизнес-аналитики (BI), является нативный механизм Writeback (обратная запись). Архитектура платформы осуществляет фундаментальный переход от классической парадигмы CRUD к архитектурному паттерну Event Sourcing (генерация событий) для бэкенда оркестрации графа. Система сохраняет каждую мутацию как отдельное, неизменяемое криптографическое событие, формируя непрерывный и строго аудируемый журнал изменений, поверх которого материализуется актуальное состояние графа объектов.
Инфраструктура обработки: Multimodal Data Plane (MMDP)
Инфраструктурной базой, обеспечивающей сбор, хранение и обработку информации для питания онтологии в Foundry, выступает архитектура Multimodal Data Plane (MMDP). Эта подсистема спроектирована для работы с беспрецедентным разнообразием типов информации и имеет нативную поддержку формата Apache Iceberg, что позволяет реализовать интеграцию с нулевым копированием (Zero Copy Integration).
Вычислительная гибкость достигается за счет федеративных движков (Apache Spark, Apache Flink, DuckDB, Polars) и способности платформы бесшовно маршрутизировать вычисления во внешние облачные среды путем делегирования обработки (pushdown compute).
Технические барьеры извлечения данных
Несмотря на открытость архитектуры MMDP на вход, существует асимметрия интеграции: легкость ввода при сложности вывода. Экспорт данных сопряжен со строгими ограничениями системы контроля версий (только master branch), неизменяемыми настройками конфигурации и жесткими политиками безопасности (необходимость роли ISO и снятия грифа секретности с маркировок). Palantir работает как высокоэффективная гравитационная ловушка для корпоративной информации.
Искусственный интеллект: Архитектура AIP
AIP (Artificial Intelligence Platform) представляет собой инструмент оркестрации, внедряющий строгий семантический контекст онтологии непосредственно в пространство генеративных вычислений.
Фундаментальным архитектурным нововведением является парадигма «k-LLM». Платформа осознает риски галлюцинаций одиночных моделей и позволяет безопасно объединять результаты вычислений нескольких различных моделей (коммерческих и open-source), создавая консенсусную систему оценки с пошаговыми логическими рассуждениями. Для операционализации используются инструменты AIP Logic (визуальная среда разработки) и AIP Evals (фреймворк тестирования с применением стратегии LLM-as-a-Judge).
Непрерывное развертывание: Платформа Apollo
Все вычислительные модули развертываются через платформу непрерывной доставки Palantir Apollo. Архитектура базируется на топологии Hub and Spoke.
Ключевое отличие Apollo — отказ от жестко заданного целевого состояния инфраструктуры в пользу непрерывного развертывания на базе ограничений (Constraint-Based Continuous Deployment). Движок оркестрации функционирует как математический решатель, который сопоставляет новые релизы, локальные ограничения среды и фактические метрики производительности для автоматического повышения версий по каналам.
Информационная безопасность: PBAC
Классические методы RBAC и ABAC в платформе дополнены запатентованным механизмом управления доступом на основе целей (Purpose-Based Access Control — PBAC). Пользователь запрашивает доступ не к таблицам, а к конкретной операционной «Цели».
Соблюдение политик обеспечивается механизмом Маркировок безопасности (Security Markings). Маркировки работают по принципу конъюнктивной логики (Boolean AND) и автоматически распространяются (Lineage Propagation) по графу вычислений, наследуясь всеми производными массивами данных и дашбордами.
Методология внедрения: Forward-Deployed Engineering (FDE)
Инженерная модель FDE физически внедряет разработчиков (Delta) и стратегов (Echo) в повседневные операции клиента. Технологическое превосходство Palantir достигается за счет глубокого институционального понимания, извлекаемого инженерами из бюрократических структур заказчика и кодируемого в архитектуру платформы.
Критический анализ и социотехнические риски
Иллюзия специализированной математики: Независимый аудит компании Lokad выявил, что платформа обладает высокой архитектурной целостностью, но критически низкими показателями в части специализированной математической логики (например, вероятностного прогнозирования для цепочек поставок). Ценность системы обусловлена интеграционной мощью, а не продвинутым математическим стеком.
Феномен Vendor Lock-in: Использование проприетарной информационной магистрали порождает колоссальный риск привязки к вендору (vendor lock-in). Невозможно разработать решение для экспорта сложного графового контекста наружу без содействия Palantir. Платформа становится «обязательной точкой прохода» (obligatory passage point), выход из которой технически разрушителен.
Социотехническая трансгрессия: Внедрение платформы в Национальную службу здравоохранения Великобритании (NHS) спровоцировало сопротивление из-за рисков для конфиденциальности и проникновения технологий военного назначения в гражданские структуры.
Культура инцидентов:
Чрезмерная зависимость операторов от сложных многоуровневых интерфейсов часто приводит к системным сбоям, которые списываются на «человеческий фактор», маскируя реальную проблему когнитивной перегрузки инженеров интерфейсами платформы.
Источники
1. The Ontology system • Palantir
2. Understanding Palantir’s Ontology: Semantic, Kinetic, and Dynamic Layers Explained
3. Rethinking the Foundry job orchestration back end: From CRUD to event-sourcing | Palantir Blog
4. The Multimodal Data Plane • Palantir
5. Evaluating Generative AI: A Field Manual — Palantir Blog
6. Palantir Apollo Orchestration: Constraint-Based Continuous Deployment For Modern Architectures
7. Purpose-based access controls at Palantir
8. Concepts • Markings • Palantir
9. A Comprehensive Analysis of Palantir’s Forward Deployed Engineering Model
10. Review of Palantir, Enterprise Operations Platform Vendor — Lokad
11. The Problem with Palantir – HASH Blog
12. Briefing: Concerns Regarding Palantir Technologies and NHS Data Systems — Medact




